dl019: standarddatensätze
Intro (00:00:00)
Thema des Podcasts (00:00:18)
Willkommen zur neunzehnten Folge beim datenleben-Podcast, dem Podcast über Data Science.
Wir sind Helena und Janine und möchten euch die Welt der Daten näher bringen.
Wie können wir mit Data Science und Daten lernen? Was brauchen wir um Anwendungen verstehen zu können?
Wer schon immer mehr über Data Science wissen wollte, ist hier genau richtig.
Thema der Folge (00:00:40)
- Heute geht es quasi um das Lernen: wer lernt, etwa Data Science spezifische Anwendungen, wird immer mit Beispielen überschüttet
- Dabei bleiben diese Beispiele über die Jahrzehnte identisch, wenn sie sich ein Mal bewährt haben
- Diese Beispieldaten -- oder auch Standarddatensätze -- haben also oft eine längere Geschichte
- Und manchmal ist diese gar nicht so unproblematisch
- Deswegen geht es heute um solche Daten und darum, dass wir mal hinsehen wollen:
- Woher kommen diese Beispiele?
- Sind sie noch zeitgemäß?
- Welchen Zweck sollen sie erfüllen?
Warum ist das Thema relevant? (00:01:56)
- Wir haben selbst solche Standarddatensätze schon benutzt, z.B. in dl013: datenvisualisierung
- Dann sind wir auf Twitter darauf aufmerksam geworden, dass der Datensatz mit den Irisblättern von einem Menschen eingeführt wurde, den wir vielleicht nicht reproduzieren wollen
- Die Frage war: Ignorieren wir diesen Hintergrund der Daten oder setzen wir uns kritisch auseinander?
- Wir haben uns natürlich für letzteres entschieden
Einspieler: Standarddatensätze und warum es sie gibt (00:02:42)
Herr von Ribbeck auf Ribbeck im Havelland,
Ein Birnbaum in seinem Garten stand,
Und kam die goldene Herbsteszeit,
Und die Birnen leuchteten weit und breit,
Da stopfte, wenn’s Mittag vom Thurme scholl,
Der von Ribbeck sich beide Taschen voll,
Und kam in Pantinen ein Junge daher,
So rief er: „Junge, wist’ ne Beer?“
Und kam ein Mädel, so rief er: „Lütt Dirn,
Kumm man röwer, ick hebb’ ne Birn.“- Theodor Fontane schrieb 1889 eines der bekanntesten deutschen Gedichte:
- Herr von Ribbeck auf Ribbeck im Havelland
- Noch immer in den Lehrplänen und erfreut oder quält Schüler*innen seit Generationen
- An dem Gedicht wird gezeigt, wie man analysiert, Versmaß bestimmt und so weiter
- Einmal etabliert und gemocht, wird es von Lehrer*innen immer wieder aus der Mappe gezogen, eine Unterrichtseinheit, immer schon fertig
- Und das ist eigentlich ein ziemlich praktisches und effizientes Vorgehen.
- Was wäre die Lehre aufwändig, wenn sich Lehrerinnen und Dozeninnen immer selber dichten müssen?
- Und genau so funktionieren auch Standarddatensätze für Programmiersprachen wie Python oder R
- Sie erfüllen einen bestimmten Zweck, sie eignen sich um konkrete Anwendungen, Funktionen und Prozesse deutlich zu machen Wie importiere ich Daten? Warum sollte ich Daten bereinigen? Wie sortiere ich Daten nach verschiedenen Kategorien oder alphabetisch? Was passiert, wenn ich Lücken in meinen Daten habe? Wie erzeuge ich aus den Daten einen verständlichen Plot?
- Und warum sollte man die auch ändern, sie funktionieren ja wunderbar.
- Aber: Sollten wir wirklich alle Standarddatensätze immer weiter benutzen?
- Und was gibt es für Punkte, die vielleicht neue oder ergänzende Standarddatensätze nötig machen?
- Die Programmiersprachen entwickeln sich, die Menschen und die Welt um sie herum entwickeln sich
Was ist problematisch am Irisdatensatz? (00:05:53)
- Dann kommen wir doch direkt zum Kern der Sache: Warum diese Folge hier?
- Wir haben in Folge 13 Datenvisualisierung auch über den Irisdatensatz gesprochen
- Dieser Datensatz ist standardmäßig in der Programmiersprache R enthalten
- Daher wird der viel auch in der Lehre genutzt, weil jeder*m automatische diese Daten vorliegen
- Nach Veröffentlichung der Folge, stolperten wir über einen Tweet mit berechtigter Kritik an diesem Datensatz
- Wirft die Frage auf: Sollten wir diesen Datensatz also künftig gegen etwas anderes ersetzen?
- Kritik: Der Mensch der den Iris-Datensatz eingeführt hat war Eugeniker
- Kurz gefasst ist Eugenik die Idee man könne die Menschliche Population durch kontrollierte Fortpflanzung zu verbessern
- Vor dem zweiten Weltkrieg in weiten Teilen der Wissenschaft bereits recht populär
- Eugenik wurde insbesondere ab 1933 wurde in Deutschland aktiv von den Nazis umgesetzt
- Mit Gesetzen, wer wen heiraten, wer Kinder kriegen darf, zu Zwangssterilisationen und erzwungenen Abtreibungen
- Extremform der Eugenik wurde von den Nationalsozialisten als sogenannte "Rassenhygiene" betrieben
- Problem an diesem Menschen mit dem Irisdatensatz: Er war leiter einer wissenschaftlichen Zeitung über Eugenik und hat nach dem Zweiten Weltkrieg die Praktiken der Nationalsozialisten weiterhin verteidigt und für in Ordnung befunden
- Grundsätzliches Problem ist hier, wie oft: Jemand entscheidet für andere Menschen, wie diese sich zu verhalten haben, und wer dabei als 'gut' angesehen wird.
- Und deswegen finden wir: unnötige Reproduktion solcher Menschen muss nicht sein, solange es sich vermeiden lässt
- Das ist der Kontrast zu vielen anderen aus der Geschichte, wie etwa Luther und Kant
- Luther war auch Rassist und Antisemit, dennoch geht eine der großen Kirchen der Religionsgemeinschaften in diesem Land auf ihn zurück
- Das heißt man kann ihn nicht komplett ignorieren, gleiches gilt für Kant
- Als Philosoph hat er grundlegendes geleistet, auf das sich noch immer zahlreich bezogen wird
- Das ist der Unterschied zum Beispieldatensatz, es geht hier nur um einen Beispieldatensatz für Grafiken oder um bestimmte Analysemodelle zu verdeutlichen – den kann man leicht ändern
- Was benutzen wir denn jetzt stattdessen?
Warum sind Pinguine besser als die Blütenblätter? (00:11:47)
- Wir wollen nicht nur kritisieren, sondern auch aufzeigen, was stattdessen möglich ist
- Es geht darum für bestimmte Beispiele Daten zu haben, um mit diesen etwas zu zeigen
- Ein Kritikpunkt am Irisdatensatz ist, dass er sperrig ist, wenn man nicht selbst Botanik gut kennt
- Ein Datensatz der besser geeignet und viel nachvollziehbarer ist und ohne belastende Geschichte:
- Der Datensatz der Palmerpenguins, erhoben von Dr. Kristen Gorman
- Bereitgestellt als R Paket von Allison Horst und Alison Hill
- Daten stammen von der Palmerstation in der Antarktis, wo u.a. Pinguine erforscht werden
- Enthalten sind zum Beispiel dann Schnabelmaße der verschiedenen Pinguinarten
- Helena verwendet für ganz simple Beispiele auch gerne den Datensatz mtcars, der in R drin ist
- Sie hat zwar keinen Schimmer was die ganzen Spalten alle bedeuten, aber wenn es darum geht zu Zeigen wie ein Bestimmter Plot verwendet wird, ist der Datensatz ganz nützlich
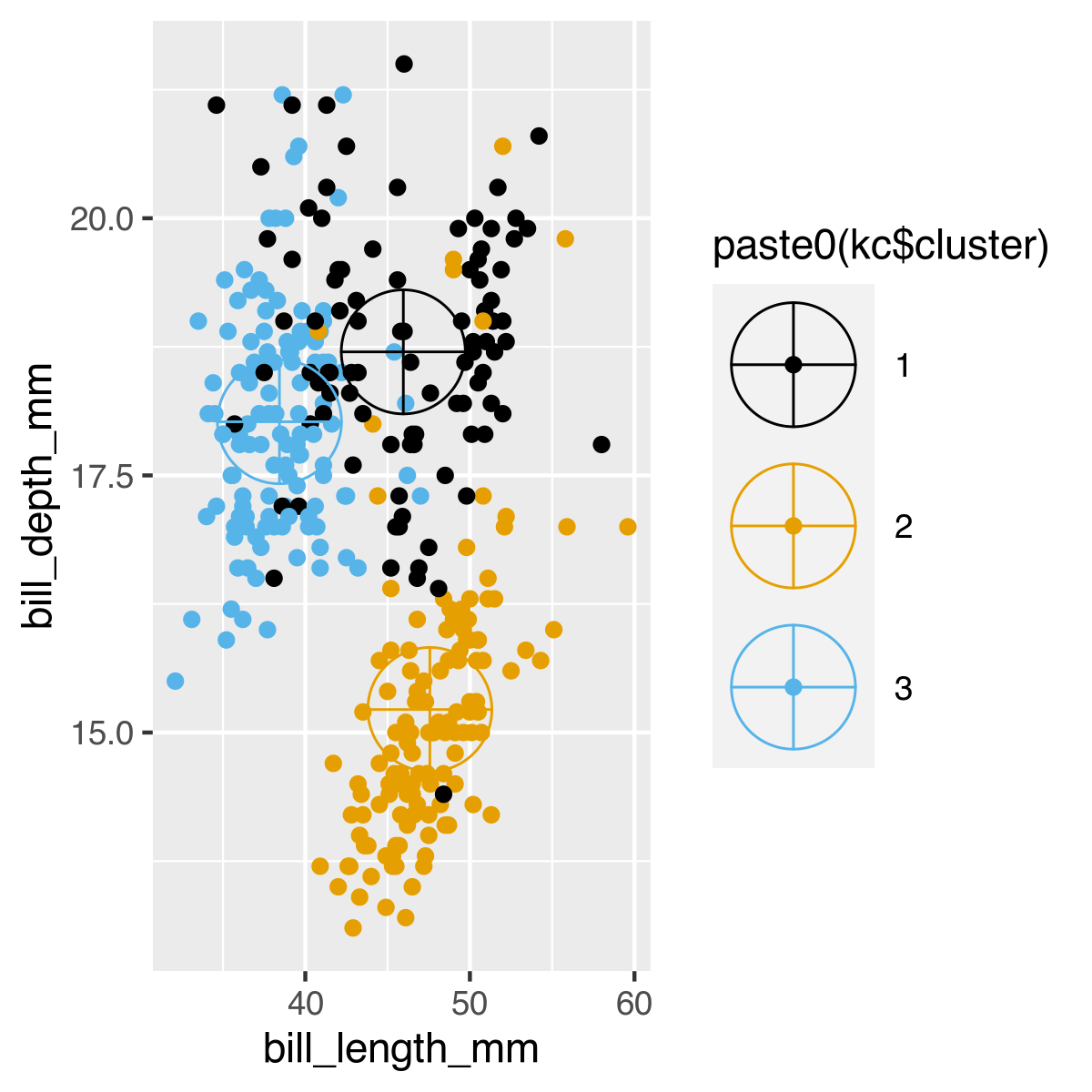
- Hier nochmal die Visualisierung mit Pinguinen statt Irisblütenblättern aus dl013: datenvisualisierung
- Es geht um das Clustering/das Darstellen der Cluster in diesen Daten
install.packages("palmerpenguins")
library(palmerpenguins)
library(ggplot2)
library(ggthemes)
# Based on: http://rischanlab.github.io/Kmeans.html
#Create the Dataset:
x = penguins[,c(-1,-2,-6,-7,-8)]
x <- na.omit(x)
y = penguins$species
kc <- kmeans(x,3)
kc$centers
plot_cluster <- ggplot(x) +
geom_point(aes(bill_length_mm,bill_depth_mm, colour=paste0(kc$cluster)))
plot_cluster + geom_point(
data = as.data.frame(kc$centers[,c("bill_length_mm", "bill_depth_mm")]),
aes(bill_length_mm, bill_depth_mm, colour=paste0(1:3)),
shape=10, size=15) +
scale_colour_colorblind()
plot_actual <- ggplot(penguins) +
geom_point(aes(bill_length_mm,bill_depth_mm, colour=species)) +
scale_colour_colorblind()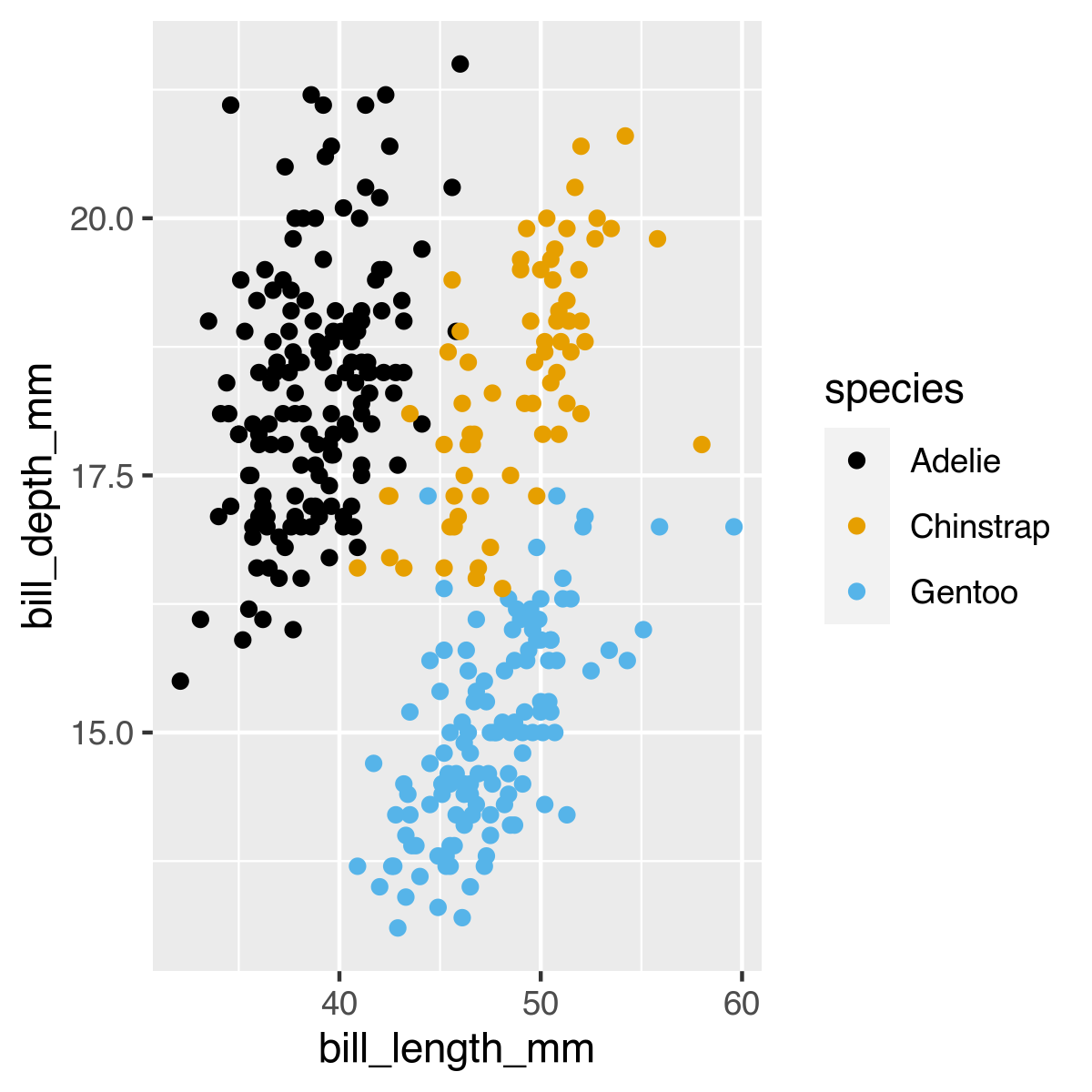
- Schön an diesem Datensatz ist ausserdem, dass er realistischer ist, weil Daten fehlen
- Man muss die Daten vor der Anwendung noch bereinigen, ehe man sie benutzen kann
- Das fertige Clustering sieht auch etwas weniger deutlich aus, als das der Irisdaten
- Auch das ist aber dadurch ein deutlich realistischerer Datensatz
Was zeigt uns der Titanicdatensatz? (00:17:42)
- Es gibt darüberhinaus natürlich noch viel mehr Beispieldaten, die immer wieder auftauchen
- In einem R-Kurs, an dem ich teilgenommen habe, gab es zum beispiel einen Datensatz mit Chartplatzierungen der letzten Jahrzehnte
- Also auch Namen, die einem vielleicht gar nicht mehr richtig viel sagen
- Allerdings ist das auch für den Anwendungsfall insofern egal, als es auch um die übung geht, die damit erzielt werden soll
- Es soll ein bestimmter Prozess veranschaulicht werden, eine bestimmte Idee die Daten zu benutzen
- Zum Beispiel Sortieren nach: Chartplatzierung, Bandnamen oder eben einzelne Künstler*innen rauspicken und nur deren Alben anzeigen
- Das Ziel konnte gut erfüllt werden auch ohne zu wissen, wer die einzelnen Bands sind
- Jeder beispieldatensatz hat also auch ein bestimmtes ziel
- Ein weiterer ist der Titanicdatensatz
- Wofür wird der denn genau eingesetzt, Helena?
- Die Titanic war ein Schiff Titanic, das Anfang des 20. Jahrhunderts gebaut wurde
- Es wurden im laufe der Jahre viele Filme darüber gemacht
- Es galt als unsinkbar, ist dann aber auf der ersten Überfahrt gesunken
- Im Datensatz enthalten: Informationen über Passagiere dieser Fahrt
- Name, Alter, Ticketnummer, Passagierklasse (1.-3.), hat überlebt oder nicht
- Datensatz wird genutzt um Algorithmen zu überlegen, die das Ziel haben, die Überlebenswahrscheinlichkeit aus den Parametern auszurechnen
- Es ist dann eine der Übungen herauszufinden, welche Parameter aus dem Datensatz besonders die Überlebenswahrscheinlihckeit beeinflusst hat
- Außerdem ist es ein realistischer Datensatz, d.h. es fehlen auch immer wieder Informationen
- Helena hat den Datensatz auch in der Lehre verwendet um Logistische Regression zu zeigen
- Logistische Regression: Aus verschiedenen Werten soll eine Kategorie herausgefunden werden
- Mit dem Datensatz lassen sich auch Entscheidungsbäume darstellen und kennenlernen
- Man kann nach Männern und Frauen oder auch Kindern filtern
- Dann nach der Passagierklasse etc. und so konnte immer feiner verästelt werden
- Auch das macht Zusammenhänge zwischen "Hat überlebt" und "Hat nicht überlebt" sichtbar
- Entscheidungsbäume sind auch eine Möglichkeit eine Regression durchzuführen für Analysen
- Wenn jetzt etwa das Alter ein Entscheidungskriterium ist, heißt es nicht, dass es keine weiteren gibt
- Wie zum Beispiel die Passagierklasse als zusätzliches Kriterium
Warum brauchen wir auch Diversität in Standarddatensätzen? (00:24:58)
- Was am Titanidatensatz natürlich auffällt: er ist binär gedacht
- Es gibt männlich und weiblich oder keine Information, weil es ein historischer Datensatz ist
- Um aber auch Lernen und Lehre divers zu gestalten, ist auch die Frage wichtig: Was sage ich eigentlich mit diesen Beispieldaten? Welche welt vermittel ich?
- Es geht um Identifikation aber auch um das Abbilden von Diversität
- Auch Lernende und Lehrende werden natürlich besser abgeholt, wenn Datensätze auch einen Teil ihrer Lebenswelt repräsentieren
- Es wäre doch schön, auch diversere Daten zu benutzen
- Konkreter noch: Mit welchen Daten lerne ich umzugehen, welche muss ich später kennen?
- Es gibt in Deutschland zwei von einem Amt bereitgestellte Bevölkerungsdatensätze: Bevölkerungbestand und -bewegung
- Deutscher Städtetag hat diese Datensätze zertifiziert für Kommunale Bevölkerungsstatistik
- Kommunen können diese immer aktualisierten Daten abfragen
- 2019 musste aktualisiert werden, weil es den Geschlechtseintrag "divers" neu gab
- Und wenn man jetzt diesen Datensatz nimmt und sich auch die Vergangenheit anguckt, muss man berücksichtigen, dass sich die Datenlage inzwischen geändert hat
- Wenn sich plötzlich Verhältnisse ändern, kann das auch an Verschiebungen durch neue Option liegen
- Daten, die erhoben werden, können sich verändern, deswegen sollte das natürlich auch irgendwie in Lehre und Lernen Eingang finden
- Deswegen muss man den Titanicdatensatz natürlich nicht wegwerfen!, er ist weiterhin gut
- Z.B. dafür, dass Datensätze auch Strukturen gesellschaftlicher Natur aufzeigen können: Klassismus
- Es wird sichtbar, dass sich der Klassismus auch direkt auf die Überlebenschancen ausgewirkt hat
- Das ist natürlich gut, solche strukturen zu erkennen und zu lernen, welche Hintergründe es gibt, die man berücksichtigen kann
- Haben schon in dl004: racial profiling gut sehen können, wie kritisch es ist nicht zu hinterfragen woher Daten stammen und wie sie erhoben worden sind
- Welche Konsequenzen resultieren aus der Anwendung von Algorithmen auf bestimmten Daten?
- Deswegen muss auch Achtseimkeit eine Rolle spielen, welche Daten man wie analysiert
Welche Standarddatensätze gibt es beim Maschinellen Lernen? (00:30:11)
- Ein Standarddatensatz ist hier der für Handschrifterkennung: MNIST (1998)
- Es geht um Ziffern zwischen 0 und 9 als Bilder in einem 28x28 Pixel kleinem Raster
- Ziffern wurden 'normalisiert', also etwa gleiche Größe und alle schwarz-weiß
- Idee dahinter: verschiedene Algorithmen gegeneinander vergleichen zu können
- Also wie gut ist welcher Algorithmus auf diesem Datensatz im Vergleich zu anderen
- Die Daten stehen Wissenschaftler*innen zur Verfügung um Verfahren zu testen
- So lässt sich Vergleichbarkeit zwischen verschiedenen Forschungsarbeiten herstellen
- Aber: Es kann sein, dass ein Verfahren schlechter abschneidet, obwohl es sehr gut ist
- Weil es auf anderen Daten besser funktioniert und ein schlechterer Algorithmus aber auf den Standarddaten sehr gut funktioniert
- Anderes Beispiel für so einen Standarddatensatz für Bilderkennung ist der FERET-Datensatz
- FERET steht für Facial Recognition Technology
- Hier geht es auch um Vergleichbarkeit und das Erkennen von Gesichtsausdrücken
- Wie sieht das denn mit Sprache zu text aus?
- Es gibt ja Firmen die mit Sprachsteuerung eine Menge Daten produzieren, wie Siri, Alexa und so
- Da wurden ja unfertige Produkte auf den Markt gebracht und Menschen haben geholfen die Transkriptionen zu verbessern, indem sie die Gespräche anderer angehört und verschriftlicht/Texte korrigiert haben
- Was sehr viele sehr unglücklich gemacht hat, als das raus kam
- Weiteres Problem: Diese Daten gehören Firmen, aber nicht der Gesellschaft
- Um die Lücke (keine große Basis an Sprachdaten für Training von Algorithmen) zu füllen, hat die Mozilla Foundation das Projekt Common Voice ins Leben gerufen
- Texte werden in verschiedenen Sprachen eingesprochen und als offener Datensatz zur Verfügung gestellt
- Andere hören dann die Sprache gegen und testet, ob das Ergebnis stimmt
- Ziel: Entwickeln von Open Source Tools für Spracheingaben
- Transkribieren funktioniert schon länger, aber man musste zahlreiche Texte selber einsprechen, um die eigene Stimme zuverlässig erkannt zu bekommen
- Damit alle Stimmen erkannt werden können, nicht nur die eigene, braucht es Projekte wie von Mozilla
Kann man beliebige Daten nutzen? (00:38:46)
- Woher kommen eigentlich die Daten, die als Standarddatensätze genutzt werden?
- Und noch viel wichtiger: Wem gehören die Daten vielleicht?
- Es können nicht einfach beliebige Daten herangezogen werden, die man dann von nun an standardmäßig einsetzt
- Firmen erheben solche Daten, man bezahlt ja teils mit seinen Daten für die Dienste, und diese Daten geben sie nicht raus
- Die meisten Standarddatensätze kommen daher auch aus der Wissenschaft
- Unser Podcast könnte theoretisch auch eine Quelle sein für Menschen um Deep Fakes unserer Stimmen zu erzeugen
- Außer uns gibt es natürlich noch andere Menschen und Gruppen, die Sprache aufzeichnen
- Ein Beispiel ist der Datensatz der Māori die ca. 300 Stunden Sprache mit Transkript in ihrer Muttersprache angefertigt haben
- Hier war das Thema, wem sie Zugriff auf diese Daten gewähren
- Sie wollen nicht, dass westliche IT-Unternehmen ihre Daten für Produkte benutzen, die sie wiederum einkaufen müssten
- So würde auch dort wieder die gesamte Wertschöpfung hängen bleiben
- Deswegen: Sie stellen die Daten nur ihrer eigenen Bevölkerungsgruppe zur Verfügung
- Vorteile: Wertschöpfung bleibt bei ihnen, wenn sie selbst daraus Dienste entwickeln
- Auch die Macht über die Daten wird damit nicht aus der Hand gegeben (spätere Anwendungen)
- Beinhaltet auch die Erhaltung der eigenen Sprache, die früher zum Beispiel an Schulen verboten war
- So etwas betrifft ja sehr viele Sprachen auf der Welt
- In Neuseeland gerade generell größeres Thema mehr Māori-Worte wieder zu verwenden
- Aotearoa statt Neuseeland, um Māori wieder mehr von der genommenen Sichtbarkeit zurück zu geben
Fazit (00:44:42)
- Man muss die Dinge nicht so lassen, wie sie sind
- Die Welt besteht aus furchtbar vielen Daten
- Es wäre schön, wenn Lehrende hingucke, welche Beispiele sie nehmen
- Gibt es bessere, die Menschen besser abholen, die mehr Spaß machen, die auch Konsequenzen vom Gebrauch der Daten zeigen?
- Und es geht auch um Datenschutz, wenn man jetzt an die Spracherkennung denkt
- Deswegen nimmt Helena aus dieser Folge mit, dass wir uns damit mal im kommenden Jahr vielleicht beschäftigen wollen
- Zum Beispiel Gesundheitsdaten und Datenschutz
- Helena wird künftig lieber Pinguine in ihre Kurse mitnehmen, statt historisch belasteter Datenbeispiele
Nächste Folge: Drogenkonsum am 06.11.2021 (00:47:15)
- Wir gucken uns eine globale Studie zum Drogenkonsum 2020 an und haben uns Themen überlegt:
- Welche Drogen werden wie oft benutzt?
- Rauchen und Alkohol? Vergleich zu Schädlichkeit mit anderen Drogen?
- Medizinische Anwendungen?
- Kriminalisierung von Drogen?
Call to Action (00:48:11)
- Wenn ihr uns weiter hören möchtet, folgt uns auf Twitter unter @datenleben
- Oder besucht unsere Webseite: www.datenleben.de
- Hinterlasst uns gerne Feedback, wir würden uns darüber sehr freuen
- Ihr könnt uns als Data Scientists auch Buchen für Analysen oder Projekte
- Habt ihr Fragen oder Themen, die euch interessieren? Dann schreibt uns!
Outro (00:49:04)
Schlagworte zur Folge
Standarddatensätze, Beispieldaten, Lehre, Lernen, Programmieren, R, Python, Beispiele, Maschinelles Lernen
Quellen
- datenleben: dl013 daten visualisieren
- Wikipedia: Herr von Ribbeck auf Ribbeck im Havelland (Fontane)
- Wikipedia: Programmiersprache R
- Twitter, @VerbingNouns: Periodic reminder… the
irisdataset often used to teach R was: [...] - Wikipedia: Nationalsozialistische Rassenhygiene. Antinatalistische Politik und negative Eugenik
- Kristen B. Gorman et al.: Ecological Sexual Dimorphism and Environmental Variability within a Community of Antarctic Penguins (Genus Pygoscelis)
- GitHub, Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0.
- GitHub, Rischan Mafrur: K means Clustering in R example Iris Data
- Kaggle: Titanic - Machine Learning from Disaster
- Städtestatistik in Deutschland: Statistikdatensätze Bevölkerung
- datenleben: dl004 racial profiling
- Wikipedia: MNIST database
- Wikipedia: FERET (facial recognition technology)
- towards data science, Jae Duk Seo: Independent Comparative Study of PCA, ICA, and LDA on the FERET Data Set
- Mozilla: Common Voice
- Wired, Donavyn Coffey: Māori are trying to save their language from Big Tech
- zdf heute: Māori fordern Umbenennung