dl025: luftdaten
Intro (00:00:00)
Thema des Podcasts (00:00:18)
Willkommen zu unserer fünfundzwanzigsten Folge beim datenleben-Podcast, dem Podcast über Data Science.
Wir sind Helena und Janine und möchten euch die Welt der Daten näher bringen.
Was ist Data Science? Welche Daten umgeben uns? Und was können wir aus ihnen lernen?
Es wird immer wichtiger Daten in das Große Ganze einordnen zu können.
In unserem Podcast sprechen wir deswegen über Data Science anhand von Themen, die uns alle betreffen.
Thema der Folge (00:00:43)
- Endlich: die Feinstaubfolge, die dank unvorhergesehe ner Dinge eine Luftdaten-Folge geworden ist
- Und es ist auch eine Folge über Citizen Science, also die Wissenschaft, die mit und aufgrund von Bürger*innen-Beteiligung stattfindet
- Vor über einem halben Jahr haben wir zum Mitmachen aufgerufen, vielen Dank an alle, die es geteilt haben und für die Daten, die wir bekommen haben
- Sind auf Feinstaub gekommen, weil wir in der Waldbrandfolge bereits Sensoren der Sensor.Community angeschaut hatten
- Damals konnten wir in den Daten der Sensoren die Waldbrände aus Kalifornien ablesen
- Das und das jährliche Feinstaub-Silvesterfeuerwerk, erschien uns interessant genug mal mit Feinstaubsensoren zu arbeiten
- Zunächst erzählt Helena über ihre Datenauswertungsreise und danach springen wir in die Auswertung von 3 Messstationen
- Weitere Dinge: haben Sensoren der Sensor.Community mit Daten von offiziellen Messstationen des Umweltbundesamtes verglichen
- Schließlich noch zwei globale Ereignisse: Saharastaub und ein Vulkanausbruch
Warum ist das Thema wichtig? (00:02:50)
- Feinstaub fanden wir wichtig, weil u.a. durch Straßenverkehr oder Holzöfen entsteht Luftbelastung
- Das hat Einfluss auf unsere Gesundheit
- Aber es geht auch um Citizen Science, das heißt, dass auch Menschen, die keine Wissenschaftler*innen sind, Daten sammeln
- Gerade bei Feinstaub geht es auch um politische Entscheidungen, deswegen sind unzensierte Daten als Vergleiche wichtig
Einspieler: Was ist dieser Feinstaub? (00:03:57)
- was ist dieser feinstaub?
Feinstaub besteht aus einem komplexen Gemisch fester und flüssiger Partikel und wird abhängig von deren Größe in unterschiedliche Fraktionen eingeteilt. Unterschieden werden PM10 (PM, particulate matter) mit einem maximalen Durchmesser von 10 Mikrometer (µm), PM2,5 und ultrafeine Partikel mit einem Durchmesser von weniger als 0,1 µm. Quelle
- Menschen erzeugen Feinstaub: Autos, Kraft- und Heizwerke, Kamine, allgemein durch Heizen und auch sehr viel in der Industrie
- Straßenverkehr: Bremsen- und Reifenabrieb; Landwirtschaft: Ammoniak-Emissionen durch Tierhaltung
- Als natürliche Ursache gilt: Bodenerosion, kleinste Partikel, die aufgewirbelt werden
- Warum spielt das alles eine Rolle? Weil es sich auf unsere Gesundheit auswirken kann
- Feinstaubpartikel reizen je nach Größe die Schleimhäute, gelangen in die Bronchien, belasten Lungen und Herz- Kreislaufsystem, was zu ernsthaften Erkrankungen führen oder bestehende verstärken kann
- EU Grenzwerte gelten seit dem 1. Januar 2005: Tagesgrenzwert PM10 beträgt 50 µg/m3, darf nicht öfter als 35mal im Jahr überschritten werden, zulässiger Jahresmittelwert 40 µg/m3
- Für PM2,5 gilt seit 2008 ein Zielwert von 25 µg/m3 im Jahresmittel
- Es gibt also gute Gründe, um Feinstaub im Blick zu haben und es ist auch gut, wenn das nicht nur der Staat macht, sondern alle Menschen sich einfach einklinken können und mit eigenen Sensoren zu einem Großen Netzwerk beitragen können
- So zum beispiel in das große Netzwerk der Sensor.Community
- Auf der Karte der Sensor.Community sind über 14.000 Sensoren registriert aus 73 Ländern
- Es sind ganz verschiedene Sensoren an der Datenerhebung beteiligt
- U.a. der Feinstaub-Sensor SDS011, der die beiden Partikelgrößen PM10 und PM2.5 messen kann
- Meist weitere Sensoren enthalten: Temperatur, Luftfeuchtigkeit, Luftdruck
- Jeder registrierte Sensor liefert frei zugängliche Daten aus
- Wer sich daran beteiligt ist Teil eines globalen Sensornetzwerkes das open data Umweltdaten generiert
- Offen zugängliche Daten sind toll, sie fördern Bürger*innen-Beteiligung, Transparenz, Wissenschaft
Wie können die Daten geladen werden? (00:07:04)
- Unsere Idee: Selbst Feinstaubsensoren zu betreiben und auszuwerten
- Aufbau: Zeitspanne ein halbes Jahr, sollte Silvester (Feuerwerk) enthalten, gleiche Sensoren
- Datensammeln: Sensoren aufbauen, anschließen, verbinden und in der Sensor.Community registrieren
- Parallel versucht bestimmte Ereignisse zu erfassen, bei denen wir dachten, da passiert was
- Wie komme ich an die Daten dann ran, wenn ich sie auswerten möchte?
- Also wie erreiche ich zum Beispiel die Schnittstelle zu den Daten?
- Und gleich als zweite Frage hinterher: Was mache ich dann, wenn ich die Daten runtergeladen habe?
- Haben den Sensor SDS011 benutzt
- Sensor.Community bietet die Daten auf ihrem Server in verschiedenen Formen an, die einfach runtergeladen werden können
- Ein Ordner für jeden Tag und dann für jeden Sensor mit jeder Sensor-ID eine Datei
- Oder man zieht die Datei, die 1x im Monat jeweils einen Sensor-Typ zusammenfasst
- Die monatliche Datei für den Sensor SDS011 war das größte Paket: 4GB gezipte CSV-Datei
- CSV hatten wir ja schonmal erwähnt, sind im Grunde Textdateien, die Tabellen darstellen
- Gezipt heißt, dass die Datei kleiner gepackt wurde, nach dem Entpacken war sie 16GB groß
- Helenas Versuche in R die Daten ohne Entpacken zu laden waren nicht erfolgreich, es wurde immer nur ein Bruchteil der Daten geladen (mit readr::read_delim und vroom::vroom package)
- Also doch entpacken, aber das Laden scheiterte daran, dass der RAM (Arbeitsspeicher) vollgelaufen ist
- Helena hat deshalb die Daten beim Laden in R direkt gefiltert, das war aber sehr langsam
- Deswegen hat sie das Filtern manuell auf der Kommandozeile gemacht
- Unter Linux gibt es da Tools um Textdateien zu verarbeiten
- In einer CSV-Datei ist jede Beobachtung eine Zeile und darüber konnte Helena einfach alle Zeilen raussuchen mit den Sensor-IDs, die uns interessiert haben
- Das waren dann nur noch 40 MB an Daten
- Damit war es dann möglich die Daten vernünftig zu laden
jsds <- sqldf::read.csv2.sql(
"/tmp/sds/2021-10_sds011.csv",
sep = ";",
sql = "select * from file where sensor_id=XXXXX"
) cat *csv|grep 12345 >> ~/sds_data.csv- Eine Person hat uns Daten über das Excelsheet eingereicht
- Wir hatten eine Tabelle vorbereitet wo Dinge eingetragen werden konnten
- Leider stehen an vielen Stellen in den Daten der Sensor.Community verschiedene IDs zu den Sensoren, und im Datensatz steht nur die 'sensor id' und nicht alle IDs, die wir gebraucht hätten
- Zum Glück hatte die Person aber ein paar Probleme mit dem Internet
- Helena musste also nur noch nach Sensoren suchen die zum gleichen Zeitpunkt Ausfälle hatten, wie im Plot zu sehen war
- Problem mit dem Laden aller Daten umgangen, indem der Zeitraum eingeschränkt wurde
- Es kamen 66 Sensoren in Frage
- Dann habe ich einen Zeitpunkt genommen, an dem die Daten im Plot ein auffälliges Muster hatten
- Und alle Daten zu diesem Zeitpunkt geplottet, und siehe da, es passte genau einer der Sensoren, und er war sogar im richtigen Stadtteil!
- Fazit: Solche Sachen sind nicht anonym, auch wenn man die IDs weglässt, weil aus der Form in Korrelation mit anderen Daten immer noch erstichtlich werden kann, woher das kommt
- Es gibt im AirRohr also nicht nur eine ID, sondern jeder einzelne Sensor bekommt eine eigen ID, die mensch dann erstmal rausfinden muss
Was haben wir konkret beobachten können? (00:15:34)
- Was haben wir also konkret beobachten können? Oder auch nicht beobachten können?
- Bei Datenerhebung haben wir auch immer wieder draufgeschaut, was da grad passiert
- So verschiede Events, die uns da als erstes in den Sinn kamen: Wie wirkt sich Regen aus? Feinstaub durch Straßennutzung bei Trockenheit?
- Frage, die wir uns immer wieder gestellt haben: Wo kommen Peaks in den Plots her? Sind die nur lokal oder größer umkreis?
- Schnell war klar: Ursachen von Peaks dann vor allem nachweisbar wenn sie auch beobachet werden, im Nachhinein scheint uns das eher schwer
- Alles in allem schwebt die riesige Frage darüber: Was ist Kausalität und was vielleicht nur Korrelation?
- Kausalität wäre ein direkter Zusammenhang zwischen dem Beobachteten Ereignis und dem Anstieg
- Während Korrelation nur zufällig während einer Beobachtung den Wert ansteigen lässt, die Ursache daher aber ganz woanders liegt
- Erste Frage, die wir uns gestellt hatten, war, wie sah Silvester in den Daten aus?
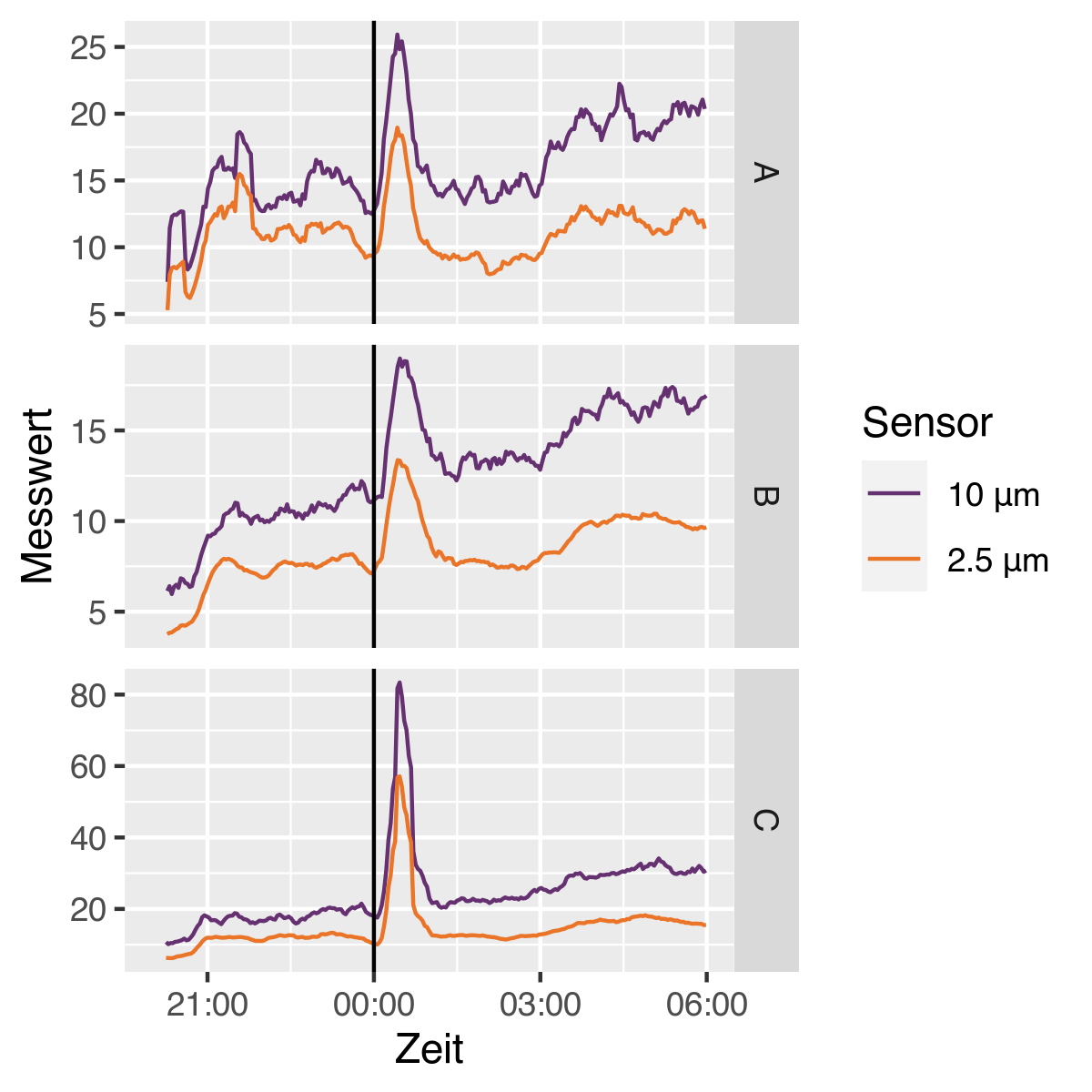
- Silvester: Wie zu erwarten ist es bei allen 3 Teststationen deutlich zu sehen
- Am stärksten etwa eine halbe Stunde nach Mitternacht
- Trotz Feuerwerksverkaufsverbot - also vermutlich weniger als sonst, aber gut zu sehen immer noch!
- Grillen: hier erwartet man eine erhöhte Feinstaubkonzentration, zumindest bei Holzkohle und Briketts
- Janine hat ein Mal gegrillt, überwiegend Briketts, so um 15:20 wurde der Grill angemacht
- Dabei hat sie live auf den Sensor geguckt, vorher war der PM10 Wert bei 10 etwa
- Als es dann richtig rauchte, ging PM10 bis auf 70 hoch, aber schnell wieder abgeflaut
- Danach passierte etwa 20 Minuten nichts und Janine hat die konkrete Beobachtung beendet
- Helenas Beobachtung in den Daten: Nachdem der Grill angemacht wurde, gab es einen kleinen Peak und ging dann wieder runter
- Eine halbe Stunde später kam erst der deutlich größere Anstieg mit mehr Feinstaub
- Es ist vorstellbar, dass wegwehende Asche auch Feinstaub verursacht, aber nicht schon so kurz nach dem anwerfen des Grills vermutlich
- Spannend wird es in Kombination mit den Daten von Helga, die auch ein Grillevent in den Daten hat, bei dem auch 30 Minuten nach anmachen des Grills die Werte steigen
- Helga hat einen Elektrogrill benutzt und trotzdem einen ähnlichen Anstieg wie bei Janine gehabt
- Also scheint Feinstaub beim Grillen insbesondere von der Nahrung zu kommen. (Hypothesenbildung)
- Daraus könnte man eine Versuchsreihe entwickeln: mehrmals grillen mit und ohne Grillgut etc.
- Straßenkehrmaschine: Janine sah einmal einen Anstieg im Zusammenhang mit Straßenkehren
- Allerdings, bei weiteren Beobachtungen hat sich das nicht wiederholt: offenbar nicht für einen großen Anstieg ursächlich
- Müllabfuhr war auch völlig beliebig und konnte nicht mit Peaks korreliert werden
- Party: Auf dem Balkon unter Helga fand eine Party statt, zeitgleich ein deutlicher Anstieg der Daten
- Vermutung: Raucher*innen auf der Party auf dem Balkon
- Rauchen: Janine hatte Besuch und diese Person hat auch draußen geraucht, dabei hat sich der Wert sehr schnell verdoppelt
- Sah so aus, als sei Rauchen die Ursache, Wert war aber vorher sehr niedrig
- In den Daten sah es vor allem bei PM10 eher nach Rauschen aus, sagt auch Helena
- Allerdings der Anstieg bei PM2,5 (für kleineren Feinstaub) war höher, als der bei PM10 - das könnte mehr als Rauschen gewesen sein
- Hier wäre eine Versuchsreihe mit Raucher*innen auch eine Möglichkeit das zu ergründen
- Später am Abend gab es noch zwei Ausschläge, während noch eine zweite Person da war, die ebenfalls geraucht hat und die natürlich zusammen rauchen gegangen sind, da liegen leider keine Zeiten vor
- Regen: Anfangs hat Janine oft, wenn es geregnet hat, den Sensor live beobachtet
- Dabei ist aber überhaupt kein Muster entstanden, das irgendwelche Rückschlüsse erlaubt hätte
- Die Schwankungen während Regen wirkten dabei sehr beliebig, mal gefallen, mal gestiegen
- Das müsste man im großen Maßsstab angucken über den gesamten Zeitraum und dazu bräuchte man auch die Regendaten
- Wir haben im AirRohr aber auch noch weitere Sensoren: Temperatur, Luftdruck und Luftfeuchtigkeit
- Bisher haben wir über Korrelation mittels Beobachtung gesprochen, die lässt sich aber auch mathemathisch definieren
- Beispiel: Man kann anhand der gleichzeitig erfassten Daten von Feinstaub und Temperatur einen Korrelationskoeffizienten erstellen
- Wenn die Korrelation besonders hoch ist, ist der Wert bei 1
- Immer wenn ein Feinstaub hoch geht und gleichzeitig die Temperatur hochgehen würde, wäre der Korrelationskoeffizient bei 1
- -1 wäre er, wenn das eine immer hoch geht, während das andere immer runter geht
- 0 wäre er, wenn es gar keine Korrelation gibt
Der Korrelationskoeffizient, auch Produkt-Moment-Korrelation, ist ein Maß für den Grad des linearen Zusammenhangs zwischen zwei mindestens intervallskalierten Merkmalen, das nicht von den Maßeinheiten der Messung abhängt und somit dimensionslos ist. Er kann Werte zwischen − 1 {\displaystyle -1} -1 und + 1 {\displaystyle +1} +1 annehmen. Quelle
- Zwischen Temperatur und Luftdruck konnte Helena keine Korrelation finden
- Es gab aber eine zwischen Temperatur und Luftdruck
- Nicht überraschend: Barometer (Gerät für Luftdruckanzeige) können benutzt werden, um kurzfristige lokale Wettervorhersagen zu tätigen
- In Sachen Korrelationen haben wir uns dann noch Messstationen vom Umweltbundesamt dazugeholt
Stationen vom Umweltbundesamt vs. private Messstationen? (00:31:00)
- Wir wollten Messstation des Umweltbundesamtes mit denen der Sensor.Community vergleichen
- Mehr Messpunkte sind besser, deswegen noch zwei weitere UBA-Stationen rausgesucht, mit Sensoren der Sensor.Community in der Nähe
- Das sind jetzt neben Braunschweig noch Leipzig und Duisburg
- Die UBA Stationen stehen dabei jeweils an größeren Straßen, die privaten Sensoren nicht direkt an der Hauptverkehrsstraße
- Und Helena hat natürlich diese Messdaten dann zusammengeworfen
- Was kam dabei raus?

- Die verfügbaren Daten der Messstationen sind die Tagesmittel, also der Mittelwert aus 24 Stunden
- Keine Angaben gefunden von wann bis wann das gilt
- Laut Korrelationskoeffizient gute Korrelation zwischen unseren Sensoren und denen vom UBA
- Allerdings gibt es eine zeitliche Verzögerung dazwischen
- Bei Zeitreihen spricht man nicht mehr unbedingt von Korrelation, sondern von Kreuzkorrelation, da man dann die Zeitdifferenz mitberücksichtigt
- In Braunschweig sind die Tagesmittel um 2 Tage versetzt
- Bei Duisburg und Leipzig sind sie um 1 Tag versetzt
- Mögliche Erklärung 1: Der Feinstaub hat "Reiseweg" von der UBA Station zu der anderen Station
- Mögliche Erklärung 2: bei einem Tag könnte sein, dass die Zeitpunkte für die das Tagesmittel ermittelt wird unterschiedlich sind:
- Zum Beispiel von 00:00 bis 24:00 oder von 12:00 an tag 1 bis 12:00 an Tag 2.
- Bei 2 Tagen erklärt es das nicht unbedingt
- Zeitlich versetzte Korrelation heißt aber, dass der Prozess der Feinstaub erzeugt, also zum Beispiel der Verkehr, ein dies in räumlichen Abstand zu den Messtationen tut
- Und dann der Feinstaub eine gewisse Zeit braucht um sich auszubreiten. Beispiel: Diffusion oder Wind
- Unsere Sensoren untereinander waren stärker Korreliert als zum UBA
- In Duisburg sind die beiden Sensor.Community Stationen auch sehr stark miteinander korreliert (0.98)
- Heißt also, wenn dass so gut korreliert, dass lokale Ereignisse wirklich nur geringen Effekt haben und zwar kausal sein können, aber trotzdem im rauschen der umgebung untergehen?
- Im Grunde ist Rauschen eine Summe ganz vieler kleiner Ereignisse
- Also kann man (Beispiel Rauchen) durchaus ein kausales Ereignis beobachten, es sieht dann aber am Ende trotzdem wie Rauschen aus
- Wenn man weiß wie ein Ereignis aussehen muss, kann das doch in den Daten gefunden werden
Was macht der Saharastaub in meinem Sensor? (00:40:56)
- Mitte März färbte Saharastaub den Himmel
- Dieser wird in der Sahara aufgewirbelt, durch Turbulenzen und Windböen in höhere Luftschichten und wird von dort mit Höhenwinden über den Globus verteilt
- Kleine Randbemerkung: Staub dieser Staub enthält Mineralstoffe, die damit verteilt werden
- Der Amazonas profitiert davon auch, Saharastaub ist Teil des globalen Nährstoffkreislaufes
- Es gibt pro Jahr etwa 5-15 Saharastaub Ereignisse, die sich etwa über 10-60 Tage pro Jahr strecken
- Und nachdem wir ja eh den Sensor im Blick haben, dachte ich: misst mein Sensor den eigentlich auch?
- Deswegen haben wir dann beschlossen das auch nochmal näher anzugucken
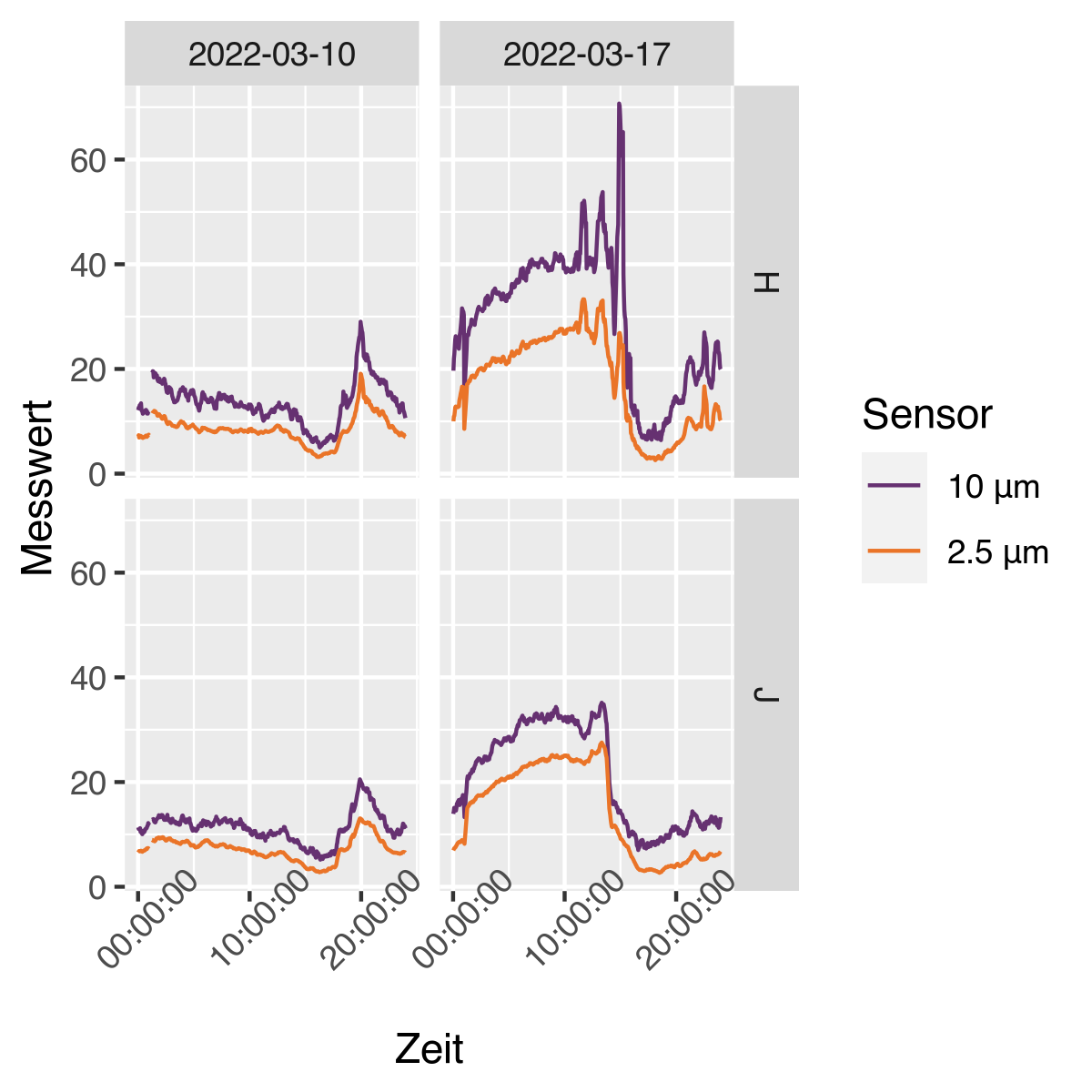
- Vergleich der Daten vom 10.3.2022 mit den Daten am 17.03.2022: es ist deutlich zu sehen dass mehr Feinstaub in der Luft ist
- Eine Woche vorher, um Wochentagseffekt auszuschließen
- Am 10.03. war der Wert deutliich unter 30 und am 17.03. im Schnitt zwischen 30-40
- Wahrscheinlich haben Menschen im Süden und Westen Deutschlands höhere Werte messen können
- Dort war der Saharastaub deutlich länger und vermutlich auch in höherer Konzentration in der Luft
- Helena hätte gerne eine Animation über alle Sensoren mit der Ausbreitung der Wolke gemacht
- Aber uns lagen noch nicht die Märzdaten als Gesamtpaket vor
- Vielleicht hat ja jemand anderes noch Lust das zu machen
- Wer mehr darüber wissen möchte, kann beim Deutschen Wetterdienst vorbeischauen
Wie können meine Sensoren einen Vulkanausbruch messen? (00:45:27)
- Am 15. Januar brach der Vulkan Hunga Tonga–Hunga Ha'apai aus
- Spannende Twitterthreads dazu sind in diesem Thread zusammengetragen:
- Die Druckwelle war so enorm, dass sie sich um die gesamte Erde ausgebreitet hat
- Es gab auch interessante Sattelitenbilder, die zeigten, wie diese Druckwelle starke Wellenmuster in die wolken "zeichnete"
- Durch die Bewegung der Luftmassen, hat sich am Rand der sich ausbreitenden Welle kurzfristig der Luftdruck verändert
- Das konnte von Luftdrucksensoren gemessen werden, auch in dem von Janine
- Der Vulkanausbruch war buchstäblich auf der anderen Seite der Erde
- Helena hatte die Idee, die Sensoren aus der Sensor.Community zu nutzen, um die Ausbreitungsgeschwindigkeit der Druckwelle zu bestimmen
- Gestartet wurde erstmal mit ein paar Drucksensoren, die das gleiche Modell hatten wie der von Janine
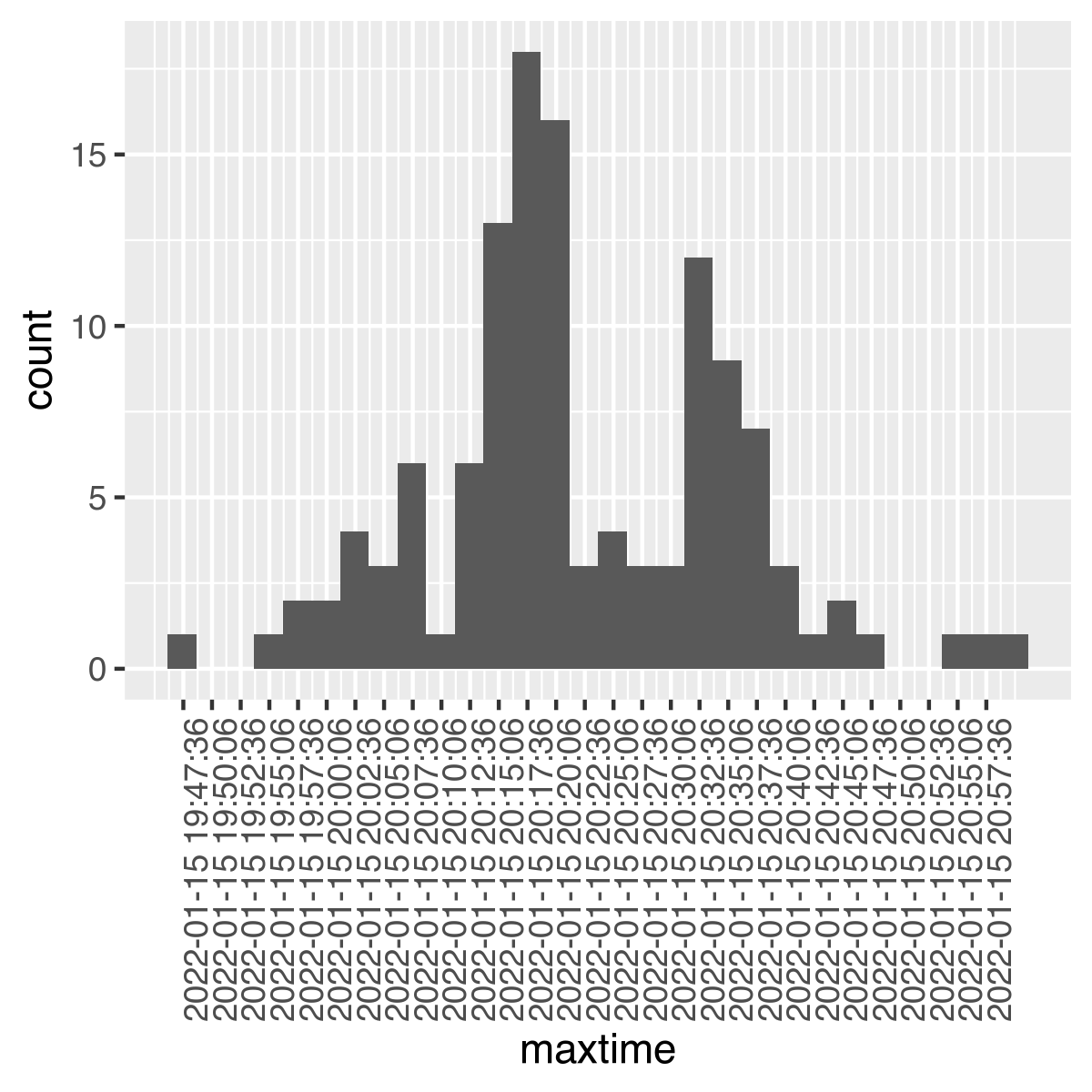
- Das waren etwa 140 Sensoren, also alle einfach erstmal geplottet -> Exploration der Daten
- Dabei fielen zunächst zwei Dinge auf:
- Ein paar Sensoren hatten offensichtlich keine Sinnvollen Daten, hochgeladen, sondern waren eher
rauschen oder ähnliches, die ließen sich manuell aussortieren - Außerdem war die durchschnittliche Zeit zwischen zwei Messpunkten ca. 150s
- Charakteristische Form der Druckwelle: Ein starker Anstieg und danach ein Abfall unter das vorherige Niveau und sich dann wieder normalisierte
- Helena hat die Daten nach Zeit gefiltert: ungefähr danach, wann die Druckwelle hier ankam
- Außerdem alle Messstationen aussortiert, die mehr als 2000km von Braunschweig entfernt waren
- Annahme der Auswertung ist, dass sich die Druckwelle als planare Welle bewegt und die Erde flach ist
- Das ist beides auf globalem Maßstab falsch, daher wird ein kleiner Ausschnitt der Welt gewählt, wo das nah genug dran kommt (Typisch Physik^^)
- Dazu musste sie wissen: Wann ist das Maximum? Wo sind die Messsensoren?
- Die Orte lagen als GPS-Koordinaten vor, bzw. genauer im WGS84 Koordinatensystem
- Da die Annahme war dass die Erde im Ausschnitt ausreichend flach ist, wurde das Koordinatensystem transformiert, in eins was x und y in Metern misst, statt in Grad
- GPS ist WGS84, was den Code EPSG 4326 hat
- UTM32U ist ein Koordinatensystem, was große Teile Deutschlands rastert, planar in Metern
- UTM32: https://de.wikipedia.org/wiki/UTM-Koordinatensystem
- WSG84: https://de.wikipedia.org/wiki/World_Geodetic_System_1984
- EPSG: https://de.wikipedia.org/wiki/European_Petroleum_Survey_Group_Geodesy
- Gemeinerweise hat das R Paket raster latitude und longitude vertauscht gegenüber dem was bei GPS üblicherweise angegeben wurde
- Auswertung 1:
- Schritt 1: Daten als Histogramm plotten, wobei sie in Gruppen von 150s eingeteilt wurden
- Schritt 2: Abschnitte auswählen, wo genug (hier über 10) Datenpunkte drin liegen
- Schritt 3: In die 4 ausgewählten Zeitausschnitte wurden dann jeweils Linien gefitted, die Latitude und Longitude miteinander verbinden
- Schritt 4: Anschauen der Fits, dabei fällt auf dass 2 der Linien überhaupt nicht passen, 2 aber ganz gut. Eine Linie sah besoners gut aus dabei
- Problem: die beiden guten Linien haben nicht die selbe Steigung, daher gibts nicht im eigentlichen Sinne einen Abstand zwischen ihnen
- Lösung/Schritt 5: Die Steigung der besser aussehenden Linie wurde auch für die zweite Linie verwendet, aber die Achsenschnittpunkt wurde neu gefittet
- Schritt 6: Jetzt wurde der Abstand der beiden Linien(genau die Differenz der Achsenschnittpunkte) durch den Zeitlichen Abstand geteilt und herauskam: 305m/s
- Das ist etwas langsamer als Schallgeschwindigkeit
- Klingt soweit auch plausibel, denn der Schall war ja auch noch sehr weit zu hören
- Wir haben hier aber nur die Druckwelle gemessen, die wir nicht hören konnten
- Es gab noch andere Luftdrucksensoren und damit noch weiter Daten in der Sensor.Community
- Alle Sensoren zusammen: BMP180, BMP280 und BME280
- Das waren deutlich mehr Daten, wo Ausreißer nicht mehr manuell vorher gefiltert werden konnten
- Daher sah die Auswertung aller Daten anders aus
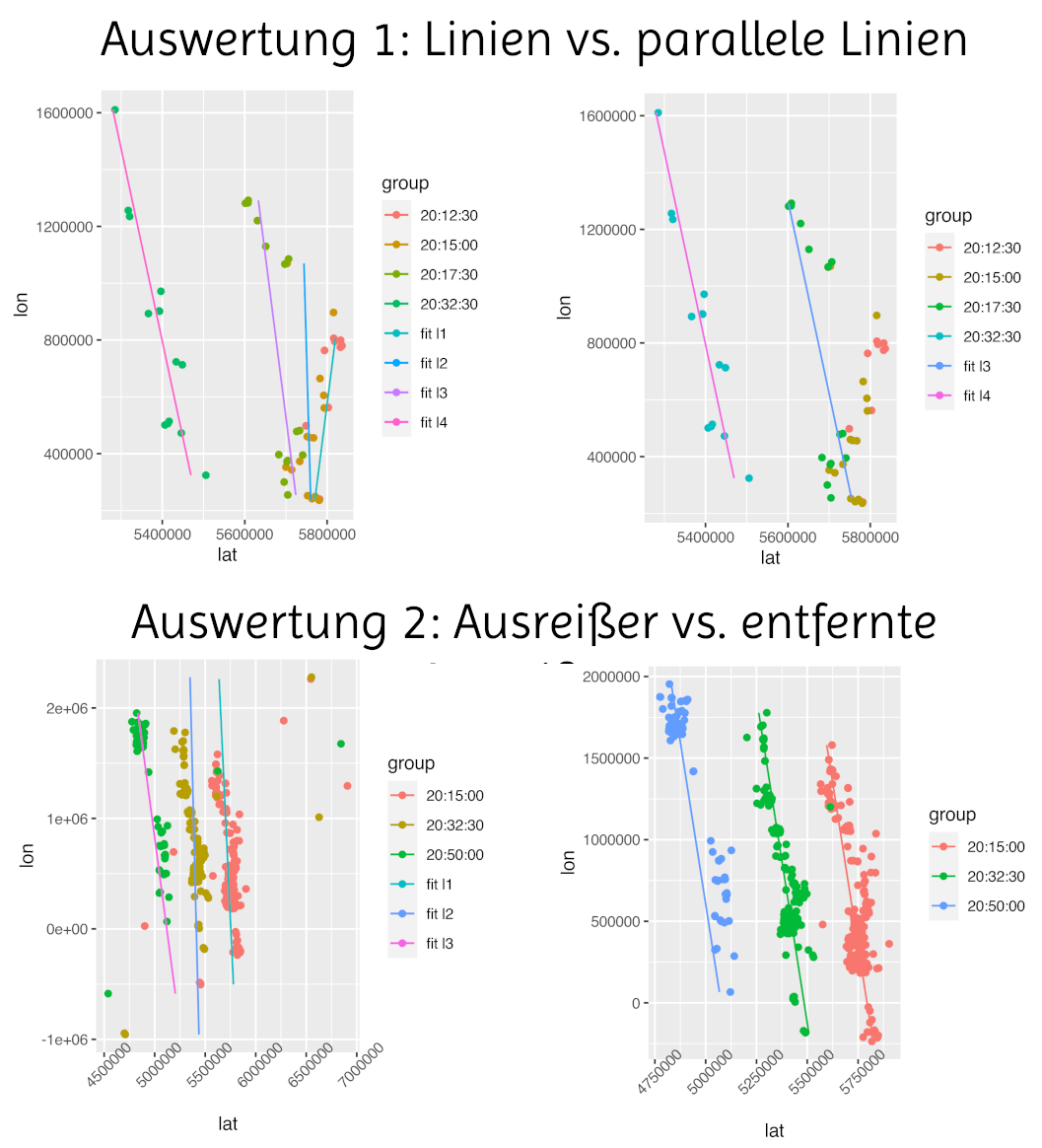
- Auswertung 2:
- Schritt 1: Daten als Histogramm plotten, wobei sie in Gruppen von 150s eingeteilt wurden
- Schritt 2: Abschnitte auswählen, wo die meisten Datenpunkte drin liegen (3 Stück)
- Schritt 3: In die 3 ausgewählten Zeitausschnitte wurden dann jeweils Linien gefitted, die Latitude und Longitude miteinander verbinden
- Schritt 4: Es gibt ziemlich üble Ausreißer, diese werden über die sogenannte 'cooks distance' ermittelt und rausgelöscht.
- Schritt 5: Nochmal fitten wie in Schritt drei, aber ohne Ausreißer
- Schritt 6: Anschauen der Fits, dabei fällt auf dass die Linien ganz ok passen, aber sie natürlich wieder andere Steigungen haben
- Schritt 7: Nochmal die Daten fitten, aber diesmal alle Daten zusammen, und alle Daten gehen in die Steigung ein, aber der Achsenschnittpunkt wird pro Gruppe einzeln bestimmt
- Schritt 8: Nochmal die Fits angucken. Diesmal sieht die Linie für Gruppe 3 etwas unpassend aus, weil die meisten Punkte an einem ähnlichen Ort liegen, und der Achsenschnittpunkt nicht richtig passen könnte, also wird diese Linie aussortiert
- Schritt 9: Jetzt wurde der Abstand der beiden Linien (genau die Differenz der Achsenschnittpunkte) durch den zeitlichen Abstand geteilt und herauskam: 304 m/s
- Damit ist die erste Rechnung verifiziert worden
- Helena hat auch nach Veröffentlichungen gesucht, die es dazu gab, diese hat sie gefunden: https://rmets.onlinelibrary.wiley.com/doi/10.1002/wea.4171
- Laut dieser lagen die Geschwindigkeiten der Druckwelle auch so zwischen 305m/s und 311m/s, wir liegen also ganz gut drin.
Fazit (01:02:05)
- Das Ziel der Folge war es, ein bisschen Spaß mit Sensordaten zu haben und zu zeigen, was damit so geht
- Zusammenfassend: im Kleinen hat das nicht so einfach funktioniert, wie Janine das dachte
- Also zum Beispiel, dass das interpretieren der Daten gerade bei lokalen Ereignissen eher schwierig ist
- Weil Ursachen ggf. einfach im Rauschen verschwinden
- Insgesamt ist es aber sehr spannend diese Daten im Blick zu haben und sich mit der eigenen Umwelt auseinander zu setzen
- Interessant fand Janine daran vor allem die globalen Ereignisse
- Helena fand das Thema spannend, weil wir eigene Daten erfasst haben und sie in die Auswertung richtig einsteigen konnte und es kamen Dinge bei raus, mit denen sie anfangs überhaupt nicht gerechnet hatte
- Das werden wir irgendwann sicherlich nochmal tun
- Wer Lust auf mehr Sensordaten hat:
- In der Sensor.Community ist gerade ein Lärmsensor in Entwicklung
- Es gibt die Option Wetterstationen mit Arduino oder Raspberry Pi zu bauen
- Visuelle Datenerfassung mittels Nistkastenüberwachung (kombinierbar mit Klimaüberwachung im Nistkasten)
- Wir hoffen es hat euch gefallen und Lust auf Sensordaten bekommen oder macht das eh schon
Was ist DivAirCity? (01:07:20)
- Es ging heute auch ein bisschen um Citizen Science dadurch, dass es Daten waren, die alle erfassen können
- Und als wir dieses Thema angekündigt hatten mit Feinstaub, wurden wir von jemandem vom Hasso Plattner Institut in Potsdam angesprochen
- Das HPI ist an einem EU-Projekt zum Thema Luftqualität in Städten beteiling: https://divaircity.eu/
- Kernpunkte des ganzen Projektes sind: Inclusive data, Empowering citizens, Smart cities contracts und knowledge sharing
- Wir unterstützen das Projekt und mal schauen, ob es da noch eine Kooperation oder auch eine Podcastfolge gibt
- Lasst uns gerne wissen, ob euch das interessiert und ihr dazu gerne eine Folge hättet
- Es ist spannend Forschung live zu beobachten
Nächste Folge? Ja, bestimmt (01:08:54)
- Unsere Nächste Folge gibt es bestimmt Ende Mai
- Wir können aber noch nicht sagen was, lasst euch einfach überraschen, was dann bei rausgekommen ist
Call to Action (01:09:19)
- Wenn ihr uns weiter hören möchtet, folgt uns auf Twitter unter @datenleben
- Oder besucht unsere Webseite: www.datenleben.de
- Hinterlasst uns gerne Feedback, wir würden uns darüber sehr freuen
- Ihr könnt uns als Data Scientists auch Buchen für Analysen oder Projekte
- Habt ihr Fragen oder Themen, die euch interessieren? Dann schreibt uns!
Outro (01:10:05)
Schlagworte zur Folge
Feinstaub, Citizen Science, Luftdaten, Temperatur, Sensor, Sensoren, Luftdruck, Gesundheit, AirRohr
Quellen
- datenleben: dl024 waldbrände
- https://sensor.community/
- Umweltbundesamt: Feinstaub
- Wikipedia: Korrelationskoeffizient
- Umweltbundesamt: Luftdaten. Stationen
- Deutscher Wetterdienst: Saharastaub
- Twitter, @NicosPanoptikum: Heute früh (5:00 MEZ) ereignete sich in der Südsee eine erneute Eruption des Vulkans auf Hunga #Tonga ...
- Twitter, @chrisoutofspace: Images from GOES-West so far. #Tonga
- Wikipedia: UTM-Koordinatensystem
- Wikipedia: World Geodetic System 1984
- Wikipedia: European Petroleum Survey Group Geodesy
- Giuseppe Petricca: Monitoring the massive Tonga volcanic explosion of 15 January 2022 from Stornoway, Scotland
- https://divaircity.eu/