dl045: jahresrückblick 2023
Willkommen zum traditionellen Jahresrückblick. Wir nehmen uns wieder Zeit, etwas über unser Podcastjahr zu reflektieren. Und dann stellen wir uns natürlich der Frage, welche Data Science Themen dieses Jahr im Fokus standen. Spoiler: wir landen wieder bei der sogenannten KI und verschiedenen Anwendungen. Und wir kommen auf einzelne Themen von vergangenen Folgen nochmal zurück, zu denen wir noch kleine Ergänzungen gefunden haben. Wie zum beispiel zu unserer Folge über Whisper oder zu den Gartenvögeln. Und am Ende fragen wir uns wieder, was uns im neuen Jahr wohl erwarten wird.
Bilder zur Folge

Links und Quellen
- datenleben
- www.datenleben.de
- Social Media: Mastodon @datenleben@podcasts.social
- YouTube: @datenleben
- Erwähnte datenleben-Folgen
- dl034: jahresrückblick 2022
- dl043: perspektiven auf data science
- dl036: graphentypen 2 – graphentypen 2 - histogramme, boxplots, etc.
- dl035: heuschnupfen
- dl001: data science
- dl021: python lernen!
- dl002: coronadaten
- dl037: citizen science und die gartenvögel
- dl042: die erde, asteroiden und wahrscheinlichkeiten
- dl038: data feminism
- dl009: jahersrückblick 2020
- dl031: können computer malen?
- dl040: wie nutzen wir whisper für transkripte?
- dl020: drogenkonsum
- Links
- BBC Reel: How artificial intelligence is helping us talk to animals
- heise online, Dr. Wolfgang Stieler: Bessere Wettervorhersage mit Künstlicher Intelligenz?
- VICE, Chloe Xiang: A Photographer Tried to Get His Photos Removed from an AI Dataset. He Got an Invoice Instead.
- Github, Acly: Generative AI for Krita
- ARD, 11KM der tagesschau-Podcast: Deepfake: Bei Anruf Klon
- AP, Larry Neumeister:Lawyers blame ChatGPT for tricking them into citing bogus case law
- OpenAI, Blog: ChatGPT can now see, hear, and speak
- Ars Technica, Benj Edwards: Google will shield AI users from copyright challenges, within limits
- The Verge, Jon Porter: ChatGPT continues to be one of the fastest-growing services ever
- NASA, Erin Morton: NASA’s OSIRIS-REx Achieves Sample Mass Milestone
- tagesschau.de, Uwe Gradwohl: Asteroidenkrümel begeistern NASA-Team
- nature mental health, Theresa R. Lii et al.: Randomized trial of ketamine masked by surgical anesthesia in patients with depression
- waldrapp.eu: Jungvögel am Flug nach Norddeutschland und Schweden
- waldrapp.eu: 32 Waldrapp-Jungvögel in Schweden, Dänemark und Norddeutschland
Schlagworte zur Folge
Jahresrückblick, KI, Neuronale Netze, Maschinelles Lernen, Sprachmodelle, Bildgenerierung, Podcastrückblick, Wissenschaft, Bennu, Citizen Science
Intro (00:00:00)
Thema des Podcasts (00:00:18)
Helena: Willkommen zur 45. Folge beim Datenleben Podcast, dem Podcast über Data Science. Wir sind Helena
Janine: und Janine
Helena: und möchten euch mitnehmen in die Welt der Daten. Was ist Data Science? Was bedeuten die Daten für unser Leben? Woher kommen sie und wozu werden sie benutzt? Das sind alles Fragen, mit denen wir uns auseinandersetzen. Wer schon immer mehr über Daten und deren Effekt auf unser Leben wissen wollte, ist hier genau richtig.
Thema der Folge (00:00:40)
Janine: Genau, und dieses Mal sage ich willkommen zum traditionellen Jahresrückblick. Inzwischen immerhin schon der vierte, den wir hier machen. Und ich hoffe, er wird genauso gern gehört wie die ersten drei. Ah ja, wir fangen wieder ein bisschen damit an, für uns das Podcastjahr ein bisschen zu reflektieren. Natürlich auch nicht ohne den Schnelldurchlauf noch davor zu setzen mit den letzten Monaten. Das Jahr ist ja noch nicht ganz voll, aber aus organisatorischen Gründen bietet es sich gerade an, jetzt den Jahresrückblick schon zu machen. Und wir haben dann auch wieder einige Themen im Gepäck. Dazu gehören eben ein paar Daten zu unseren Folgen, Ranking, Feedback. Und natürlich dann die Kernfrage, welche Data Science Themen waren dieses Jahr sehr dominant? Ja, Spoiler an dieser Stelle: Wir landen wieder bei der sogenannten KI und verschiedenen Anwendungen von eben dieser, beziehungsweise maschinellem Lernen, neuronalen Netzen und dem ganzen Zeug. Ah ja, und wir kommen auch wieder auf einzelne Themen von Folgen zurück, wo wir noch was gefunden haben, was wir vielleicht gern ergänzen würden, was vielleicht nicht in die Folgen gepasst. Zum Beispiel ist das Thema Whisper hier nochmal zu nennen oder auch die Gartenvögel-Folge und Drogen. Drogen wird es auch geben, so in etwa. Und ja, am Ende fragen wir uns dann natürlich wieder, was uns wohl im neuen Jahr erwarten wird.
Warum ist das Thema interessant? (00:02:15)
Helena: Ja, und wir machen mal wieder den Jahresrückblick, weil wir das halt als Tradition so eingeführt haben. Und das immer eine gute Möglichkeit ist, auch mal meta über den Podcast zu reden und auch eine Möglichkeit ist, mal Ergänzungen zu alten Folgen hinzuzufügen.
Janine: Ja, und jetzt viel Spaß beim Schnelldurchlauf durch Teile von 2023.
Einspieler: Jahresrückblick — 2023 im Schnelldurchlauf (00:02:39)
Janine: Jahresrückblick 2023 im Schnelldurchlauf.
* 01. Januar: Die Grundversorgung mit Hartz IV -- also das Arbeitslosengeld II -- wird vom nicht wesentlich verbesserten neuen Bürgergeld abgelöst.
* 01. Januar: In Kroation wird der Euro ab dem 01. Januar zur offiziellen Währung.
* 08. Januar: In Brasilien demonstrieren Anhänger des früheren Präsidenten Bolsonaro gegen den neu gewählten Präsidenten Lula da Silva. Hunderte stürmen währenddessen für mehrere Stunden randalierend den Nationalkongress, das Oberste Bundesgericht und den Regierungssitz Brasilia. (Nebenbemerkung: Der Sturm auf das Kapitol in Washington D.C. durch Anhänger von Donald Trump ereignete sich fast auf den Tag genau 2 Jahre zuvor, 2021.)
* 11. Januar: Im Rheinischen Braunkohlerevier beginnt die Polizei mit der Räumung des Dorfes Lützerath, das von Klimaaktivst*innen besetzt wurde, um die Förderung der Braunkohle an diesem Ort zu verhindern.
* 01. Februar: Über den USA wird ein großer chinesischer Beobachtungsballon gesichtet, der am 04. Februar von den USA abgeschossen wird, was zu diplomatischen Spannungen zwischen den beiden Staate führte. In den folgenden Tagen wurden weitere unbekannte Flugobjekte abgeschossen, die sich offenbar als Forschungsprojekte privater Unternehmen herausstellten.
* 03. Februar: Im Bundesstaat Ohio, USA, entgleist beim Ort East Palestine ein sehr langer Zug beladen mit Chemikalien. Menschen mussten evakuiert werden und die Chemikalien wurden kontrolliert abgebrannt.
* 06. Februar: Zwei Erdbeben mit den Magnituden 7,8 und 7,5 treffen den Südosten der Türkei und den Norden Syriens. Es werden mehr als 54.300 Tote geborgen und über 110.000 Verletzte registriert.
* 21. Februar: Der russische Präsident Wladimir Putin verkündet, dass Russland die Teilnahme am derzeit gültigen New START Vertrag aussetzt. Dieser Vertrag ist ein Abrüstungsabkommen zwischen den USA und Russland zur gemeinsamen Reduzierung strategischer Trägersysteme für Nuklearwaffen.
* 02. März: In der Cheops-Pyramide wird eine unbekannte leere Kammer entdeckt. Bis dahin war die Kammer aufgrund von langen Untersuchungsreihen nur eine Vermutung, die sich schließlich mit dem Fund bestätigt haben.
* 05. März: Die Vereinten Nationen einigen sich auf ein Abkommen zum Schutz der Hohen See, die jenseits staatlicher Hoheitsgewalt liegt. Bis zum Jahr 2023 sollen 30% des Gebietes unter Schutz gestellt werden.
* 17. März: In Den Haag wird vom internationalen Strafgerichtshof ein Haftbefehl gegen den russischen Präsidenten Wladimir Putin erlassen.
* 12. April: In Berlin stellen die Bundesminister Lauterbach und Özdemir Eckpunkte zur Legalisierung von Cannabis in Deutschland vor.
* 15. April: Berlin/Deutschland: Die letzten drei deutschen Kernkraftwerke werden abgeschaltet.
* 16. April: Nur einen Tag später geht im finnischen Kernkraftwerks Olkiluoto der leistungsstärkste Atomreaktor in Europa in Betrieb.
* 05. Mai: Nach 3 Jahren und 96 Tagen wird die "gesundheitliche Notlage internationaler Tragweite" beüglich der COVID-19-Pandemie von der Weltgesundheitsorganisation aufgehoben.
* 06. Mai: Die Krönung von König Charles III. und Königin Camilla wird in der Westminster Abbey vollzogen.
* 24. Mai: Die Generalstaatsanwaltschaft München leitet gegen sieben Mitglieder des Klimabündnisses Letzte Generation Ermittlungen ein. Es bestehe der Verdacht auf Bildung einer kriminellen Vereinigung.
* 06. Juni: In der Ukraine wird im Kontext des Krieges der Kachowka-Staudamm vermutlich durch eine Sprengung zerstört. Das zog gravierende Überschwemmungen nach sich.
* 12. Juni: Das Großmanöver [Air Defender 23] beginnt. Mitgliedsstaaten der NATO und weitere Staaten haben eine der größten Luftoperationsübrungen durchgeführt, die schwerpunktmäßig im Luftraum der Bundesrepublik Deutschland stattfand.
* 18. Juni: Das Tiefsee-Tauchboot namens Titan implodiert bei einer touristischen Tauchfahrt zum Wrack der Titanic. Zunächst wird eine aufwändige Suche gestartet, die Trümmerteile werden erst später entdeckt. Alle fünf Passagiere kamen ums Leben. Dieses Ereignis erregt große öffentliche Aufmerksamkeit, besonders in den Sozialen Medien.
* 01. Juli: In Australien wird weltweit erstmals die Verschreibung von MDMA und Psilocybin zur Behandlung bestimmter psychischer Erkrankungen zugelassen.
* 01. Juli: In Deutschland wird der Skywalk Willingen eröffnet. Mit einer Länge von 665 m ist es die zweitlängste Fußgänger-Hängebrücke der Welt.
* 05. Juli: Vom Weltraumbahnhof Kourou in Französchisch-Guayana startet zum letzten Mal eine Trägerrakete vom Typ Ariane 5 erfolgreich ins Weltall.
* 06. Juli: Die Niederlande kündigen an, dass sie 478 Artefakte, die in der Kolonialzeit angeeignet wurden, nach Indonesien und Sri Lanka zurückzubringen.
* Im August: Auf Hawaii, in Kanada und Griechenland gibt es über den Monat August verteilt verheerende Waldbrände.
* 01. August: Die Royal Mail führt die erste regelmäßige Postzustellung durch Drohnen ein. Auf der schottischen Inselgruppe Orkney wird die Post jetzt mit Skyports-Drohnen ausgeliefert.
* 30. August: In Kirgisistan kündigt das Ministerium für Kultur, Information, Sport und Jugendpolitik an, dass die Plattform TikTok verboten werden soll. Grund: Schutz der Gesundheit von Kindern.
* 08. September: Marrakesch/Marokko: Bei einem Erdbeben nahe Marrakesch kommen mehr als 2900 Menschen ums Leben. Dabei werden viele Bergdörfer teils zerstört und auch das Weltkulturerbe in der Altstadt von Marrakesh beschädigt.
* 10. September: Beim G20-Gipfel im indischen Neu-Delhi wird die Afrikanische Union wird als neues Mitglied der G20 aufgenommen.
* 25. September: Seit diesem Tag existiert die Bundesrepublik Deutschland länger als ihre Rechtsvorgängerin das Deutsche Reich, das von 1871 bis 1945 bestand.
* 06. Oktober: Dem im Iran inhaftierten Menschenrechtsaktivistin Narges Mohammadi wird der Friedensnobelpreis zugesprochen.
* 07. Oktober: Mit einem schweren Terrorangriff der Hamas auf Israel wird der Konflikt erneut intensiviert. Als Reaktion auf die schwere des Überfalls, ruft israelische Ministerpräsident Benjamin Netanjahu zum ersten Mal seit 1973 den Kriegszustand aus.
* 10. November: Australien schließ mit dem Inselstaat Tuvalu, der durch den steigenden Meeresspiegel bedroht ist, eine Vereinbarung. Es dürfen jährlich 280 Tuvaluer – von aktuell 11.200 Einwohnern – nach Australien übersiedeln. Sie dürfen ausserdem die australische Staatsbürgerschaft erhalten, um dort zu arbeiten, zu studieren und zu leben.
* 23. November: In Dublin greift ein Mann mit einem Messer drei Schulkinder an. In der Folge randalieren 200-300 Menschen in der Innenstadt, legen Feuer und plündern Geschäfte. Es kommt zu einem Großeinsatz der Polizei. Neben viel Sachbeschädigung und verletzten Menschen, gibt es zahlreiche Verhaftungen und 32 Anklagen.
* 06. Dezember: Die Bundestagsfraktion Die Linke löst sich auf.
* Dezember: Was uns sonst noch im Dezember erwartet, kann aufgrund der Linearität unserer Zeitwahrnehmung noch nicht gesagt werden.
Wie sehen die datenleben-daten für 2023 aus? (00:09:50)
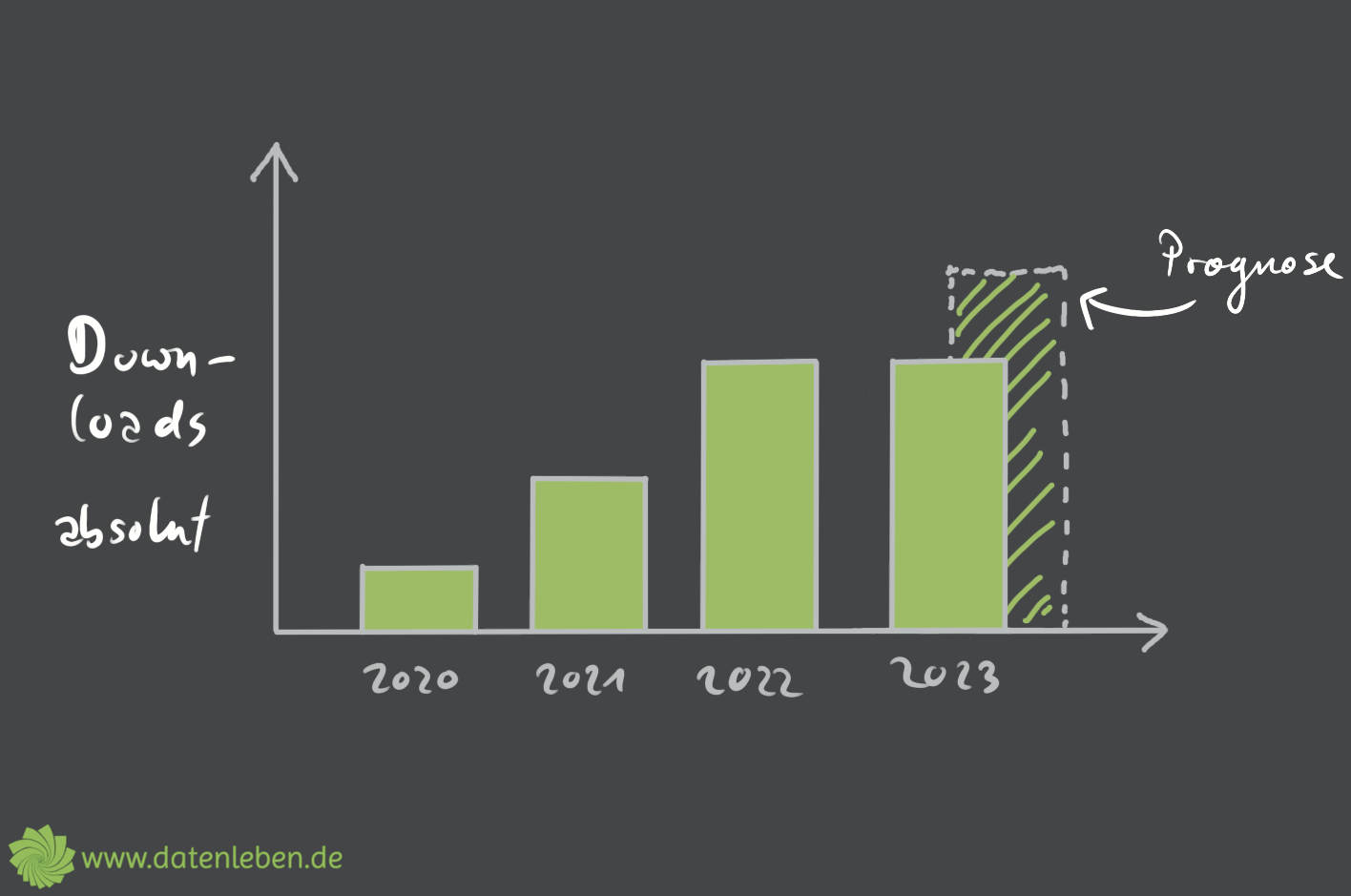
Janine: Erste Frage, erstes Thema. Wie sehen die Datenleben? Wie sehen die Daten für 2023 aus? Wir hatten letztes Jahr eine Prognose gemacht, aufgrund der Daten, die wir erhoben hatten. 2020 war unser erstes Podcastjahr. Da hatten wir eine gewisse Datenmenge bzw. Downloads im Jahr 2020, in den Monaten, in denen wir eben gepodcastet haben. Und haben dann mal geguckt für 2021, wie viel waren die Downloads da so im Verhältnis. Und es ist eine ganze Ecke gestiegen. Und auch 2022 ist wieder in etwa genauso viel Wachstum hinzugekommen, was die Downloadzahlen für das Podcastjahr anging. Also so die absoluten Zahlen quasi. Und naja, daraus hatten wir dann eine Prognose gemacht für das Jahr 2023 und einen ähnlichen Anstieg angenommen. Und das in eine kleine Grafik gezeichnet, mit einem schraffierten Balken für 2023. Und das Ganze sah relativ linear aus. So, ja, das war dann unsere Prognose für dieses Jahr, dass das Wachstum genauso bleibt. Aber kurz gesagt, das ist nicht passiert. Es ist auch nicht mehr geworden. Tatsächlich ist der Balken für 2023 zu diesem Zeitpunkt, wir machen die Aufnahme am 28. November schon, noch nicht so viel mehr wie die Jahre davor. Also der Balken für 2023 ist tatsächlich gar nicht so viel größer als für 2022. Ihr findet die Grafiken auch, die aktualisierten, in den Shownotes übrigens. Ja, also das Wachstum ist nicht dabei geblieben. Unsere Prognose traf also nicht zu.
Helena: Ja gut. Kann sich ja noch ändern, falls dieser Jahresrückblick besonders beliebt ist.
Janine: Ja, der kann noch ein bisschen was machen. Und was aber ich ganz interessant finde, ist, dass trotzdem, andere Bereiche der Zahlen irgendwie doch ganz gut gestiegen sind. Also wir haben zwar irgendwie fast genauso viele Downloads wie letztes Jahr, aber dafür haben unsere Folgen, wenn sie erscheinen, jeweils mehr Downloads am ersten Tag als letztes Jahr zum Beispiel. Das heißt also, ja, vielleicht bildet sich das Wachstum dieses Jahr anders ab, indem wir vielleicht einfach sagen können, wir haben mehr Zuhörende gewonnen, die regelmäßig auch direkt in unsere neuen Folgen reinhören.
Helena: Ja.
Janine: Ja, die zweite Grafik, die wir letztes Jahr gemacht haben, bezog sich auf die Downloads pro Tag. Da verhält sich das natürlich ganz ähnlich dann. Ich bin mal gespannt, wie sich das dann jetzt weiterentwickelt. Was die Ranglisten angeht von Folgen, gab es im Jahr 2023 ganz klare Favoriten. Überraschenderweise steht an Platz 1 eine Folge, die noch gar nicht so alt ist, nämlich die Folge 43, Perspektiven auf Data Science. Die hat die meisten Downloads dieses Jahr geholt, was die Folgen angeht. Und an Platz 2 steht tatsächlich, was mich auch überrascht, Grafentypen 2, Histogramme und Boxplots. Und Platz 3 geht an Heuschnupfen. Also viele Grüße an die Mitleidenden da draußen, die diese Folge vielleicht deswegen gehört haben.
Helena: Ja.
Janine: Und was wir auch immer einmal angucken, sind die Gesamt-Downloads über alle Jahre. Wir podcasten jetzt fast seit dreieinhalb Jahren. Und wie jedes Jahr steht unsere erste Folge an Platz 1 die Data Science-Folge, wo wir uns unseren Podcast und Data Science einmal vorstellen. An Platz 2 steht die wunderbare Folge Python Lernen, in der wir PiKo interviewt haben zum Thema Python und wie sich dieses Themenfeld so gut erschlossen werden kann, dass, ja, Punkt, dieser Satz hört einfach hier auf. Und an Platz 3 ist eine Folge, die letztes Jahr nicht in dieser Rangliste auftauchte, sondern wieder eingestiegen ist, nämlich die Corona-Daten-Folge.
Helena: Ja, das finde ich ja durchaus interessant, weil bei Corona-Daten hätte ich jetzt erwartet, ja, die Daten, über die wir geredet haben, sind ja seitdem lange outdated. Da gibt es bestimmt viele aktuellere Informationen zu. Warum ist das immer noch so interessant?
Janine: Ja, ich glaube, weil es ja auch für uns so ein bisschen die Grundlagen ja auch einmal erklärt hat. Also wie wird überhaupt der R-Wert berechnet, die Inzidenz und so. Und das verändert sich ja an sich eigentlich nicht. Nur die Daten, mit denen wir umgegangen sind, sind andere geworden.
Helena: Ja, schon. Aber wer guckt denn vor dem Download auch auf die Inhalte ganz konkret drauf, dass wir das genau erklären? Das überrascht mich nämlich. Also keine Ahnung.
Janine: Ja, also ich gucke tatsächlich bei Podcast-Folgen vorher drauf, bevor ich die downloade.
Helena: Also vorher in die Shownotes, okay.
Janine: Ja, weil ich vielen Podcasts gar nicht so unbedingt bei jeder Folge dabei bin, sondern mir tatsächlich Themen aussuche und meinem Podcatcher auch verboten habe, Sachen sofort runterzuladen, die ich abonniert habe. Und dann kann ich da sehr selektiv tatsächlich vorgehen. Vielleicht machen das Menschen auch so.
Helena: Ja, vielleicht.
Unsere Lieblingsfolgen in 2023? (00:15:23)
Janine: Gut, dann ist eine Frage, die ich immer sehr mag. Was sind denn so unsere Lieblingsfolgen aus 2023? Helena, was war denn deine Lieblingsfolge von diesem Jahr?
Helena: Ja, meine Lieblingsfolge in diesem Jahr war die über die Gartenvögel. Da habe ich ganz viel gelernt. Also nicht nur über einzelne Vogelarten, sondern eben auch wie, ja, so Messverfahren bei Tierpopulationen überhaupt funktionieren. Und dass da auch gerade so Data-Science-Projekte wie die Gartenvögel unheimlich nützlich für sind. Das fand ich sehr schön.
Janine: Ja, und das ganze Citizen-Science-Thema, was da mit drin steckt, hat mir auch sehr gefallen bei der Folge.
Helena: Ja, und was war deine Lieblingsfolge?
Janine: Ich kann mich nicht entscheiden. Ich schwanke zwischen Folge 42, Asteroiden und die Wahrscheinlichkeit, mit der sie die Erde treffen können, weil das, ich weiß nicht, ich finde, das ist einfach ein schönes Thema. Dieses ganze Weltraumzeug. Grundsätzlich. Und ja, als Kind der 90er bin ich da auch ein bisschen vorgeimpft, was die Medien, Filme und Serien angeht. Deswegen hat die besonders Spaß gemacht. Auch schon allein in der Recherche und im Zusammenstellen. Ja, und die zweite Folge ist die Data-Feminism-Folge, weil ich es einfach sehr schön fand, mich da so thematisch reinzudenken und sie zu den weniger technischen Folgen gehört, die wir gemacht haben, wo mein literaturwissenschaftliches Gehirn einfach sehr viel Spaß dran hatte. Und ich finde das Thema auch einfach sehr wichtig, unterschiedliche Perspektiven auf die Dinge zu bringen und diese auch ernst zu nehmen und nicht gleich wegzuwischen mit das ist doch Feminismus. Nein, das kann allen Menschen helfen.
Helena: Ja, fand das auch eine gute Folge.
Feedback zu datenleben (00:17:14)
Helena: Ja, außer dass wir verschiedenste Folgen veröffentlicht haben, gibt es ja auch immer mal wieder Feedback zu unserem Podcast und einiges von diesem Feedback kommt auch auf unserer Webseite an. Und in diesem Jahr gab es mal ein ganz besonderes Feedback. Und zwar haben wir Feedback von ChatGPT bekommen oder so in der Art, weil da war dann auch ein Webseiten-Link bei, dass irgendwie so ein, jemand hat ChatGPT geklont, also quasi irgendwie eine Oberfläche dafür gemacht und versucht jetzt irgendwie Werbegeld abzugreifen oder so. Und über Spam wird das Ganze dann halt, dieser Link irgendwie verbreitet, damit Leute das finden. Und ja, das Feedback kam im Juli rein, war aber auch zur letzten Jahresrückblicks-Folge, also passend. Und das möchte ich jetzt einmal vorlesen.
Lieber Datenleben-Team, ich möchte euch für diesen großartigen Jahresrückblick 2022 danken. Ihr habt es wirklich geschafft, das vergangene Jahr auf eine informative und unterhaltsame Art und Weise Revue passieren zu lassen. Die Artikel sind gut strukturiert, lesenswert und mit interessanten Informationen gespickt. Ich habe mich durch den Jahresrückblick regelrecht gewühlt und konnte so viele spannende Details entdecken. Weiter so. Herzliche Grüße, GPT[...].
Helena: Und dann der komische GPT-Klon-Name. Ja, da sind natürlich offensichtliche Fehler drin, wie man das von ChatGPT ja durchaus auch kennt. Irgendwie hat es nicht so richtig verstanden, dass es ein Podcast ist. Ich meine, seit diesem Jahr haben wir ja immerhin vollständige Transkripte. Das heißt, man kann das auch rein durchlesen machen. Aber ja, fanden wir lustig, haben wir trotzdem nicht freigeschaltet. Aber finde ich doch überraschend, dass man irgendwie, wenn man so eine Webseite betreibt, unheimlich viel Spam kriegt. Und das ist das einzige Mal, ich meine, da steht jetzt sogar, dass es von ChatGPT oder Ähnlichem gemacht ist, drin. Aber alle andere Spam passt ja überhaupt gar nicht. Da hat niemand irgendeinen GPT drauf gelassen oder ein Sprachmodell. Das ist immer wieder überraschend, dass das noch so unverbreitet ist. Obwohl das technisch doch mittlerweile so einfach sein sollte.
Janine: Wobei unser Spam-Filter gerade wieder ein bisschen besser funktioniert. Vielleicht kriegen wir es gerade nur nicht mit.
Helena: Ja, aber das ist auch erst eine Änderung in den letzten paar Monaten gewesen. Davor, wo das hier erschienen ist, war der ja noch nicht verbessert. Da hätte das auch sein können, dass man öfter sowas sieht. Aber das ist bisher noch gar nicht so passiert.
Janine: Bei uns jedenfalls nicht. Falls euch so etwas in einem Projekt, wo ihr tätig seid, begegnet ist, sagt gern Bescheid.
Was nehmen wir mit aus 2023 an Themen oder Erkenntnissen? (00:19:58)
Janine: Das war es aus dem Bereich zum Podcast. Jetzt kommt der große Abschnitt. Was nehmen wir aus 2023 an Themen und Erkenntnissen mit? Also ja, es ist halt irgendwie das große Jahr der Sprachmodelle. Und was wir beobachten, weil wir hatten dieses Thema, also künstliche Intelligenz, neuronale Netze, ja auch schon in den letzten Jahresrückblicken oder zumindest vor allem im Letzten sehr dominant. Und so langsam haben wir zumindest das Gefühl, das war so ein bisschen eine Erkenntnis, das Umgehen damit hat sich jetzt so ein bisschen verschoben von das gibt es jetzt, das ist da, damit spielen alle einmal rum, zu damit arbeiten wir jetzt wirklich produktiv. Also in unserem Alltag, teilweise auch im Beruf, hört man ja auch immer wieder. Und ja, dazu, kommen wir auf jeden Fall gleich noch in der Tiefe. Und vorher dachten wir, kommen wir noch zu den persönlichen Eindrücken. Ja, ich fange einfach mal an. Und weil ich nicht wusste, was ich machen soll, greife ich mein Thema vom letzten Jahr auf. Da habe ich im letzten Jahresrückblick gesagt, dass ich 2022 nur acht Bücher beendet habe, was mich echt ein bisschen schockiert hat. Und ich hatte mich dann damit beschäftigt, wo meine Zeit sonst reingeflossen ist. Und dann stellte sich raus, dass ich, dass ich an 75 Rollenspiel-Sessions beteiligt war. Und ich glaube, da ist so ein bisschen meine Lesezeit hin abgeflossen. Das wollte ich ein bisschen umstellen in 2023 und hatte mir das hehre Ziel gesetzt, 23 Bücher zu lesen. Muss ja irgendwie zu schaffen sein. Früher habe ich ein Vielfaches davon gelesen und die quasi weggeatmet. Und ich bin ja auch schließlich in zwei Lesezirkeln aktiv. Also irgendwas muss da gehen. Naja, die harte Realität und meine Erkenntnis damit für dieses Jahr, das sich allein vorzunehmen und zu wünschen oder gerne mal wieder zu machen, reicht nicht. Ich habe tatsächlich zum jetzigen Stand exakt acht Bücher wieder beendet, was eigentlich genauso viele wie letztes Jahr sind. Aber ich habe mehrere fast beendete Bücher.
Helena: Ja, dann hast du ja noch die Chance, dass das klappt, noch mehr zu beenden.
Janine: Genau, es werden definitiv keine 23 werden. Aber ich habe bis Ende des Jahres noch Zeit, wenigstens drei Bücher zu beenden. Dann wäre ich bei elf; ist ja auch schon mal ein Anstieg. Ja, falls sich jetzt jemand fragt, wie war denn das dann mit den Rollenspiel-Sessions? Hat sich da auch was getan? Ja, ich hatte dieses Jahr bis zum jetzigen Zeitpunkt 104.
Helena: Ja, deutlich mehr als im Jahr davor. Das Jahr ist noch nicht mal um.
Janine: Ja, es macht halt aber auch leider einfach so viel Spaß. Und irgendwo ist es ja auch das Gleiche. Man beschäftigt sich mit anderen Perspektiven, einer anderen Welt und kann sich darin reinversenken. Und das macht einfach unglaublich viel Spaß. Ja, deswegen habe ich auch ein bisschen gelernt, okay, das Steuern von Interessen klappt irgendwie einfach nicht. Das Gehirn will, was es will, ist eigentlich auch keine neue Erkenntnis. Aber hin und wieder schlägt sie wieder relativ überraschend zu. Ja, das dazu. Helena, was hast du denn für 2023 so im Blick an Erkenntnissen?
Helena: Ja, also du hast ja vorhin schon mal erwähnt, dass es offensichtlich das Jahr der großen Sprachmodelle ist. Und eine Sache, die eben auch daraus folgt, ist, um solche Sprachmodelle überhaupt trainieren zu können, muss man unheimlich viel Geld investieren. Das heißt, das ganze künstliche Intelligenz oder maschinelles Lernthema ist jetzt auch ein Thema, das mit, ja, man muss große Finanzmittel haben einhergeht. So wie das ja auch sonst immer bei, wenn man eine Fabrik bauen wollte, brauchte man viel Geld. Aber jetzt ist es auch so, wenn man ein solches Modell trainieren möchte selber, braucht man sehr viel Geld. Aber auch, um es anwenden zu können, sind die Hardware-Anforderungen ja doch deutlich größer, als zum Beispiel, als wir letztes Jahr noch über die Bildgenerierung geredet haben. Also, das heißt, auch hier kommen höhere Kosten auf einen zu, wenn man das einfach nur mal selber damit entwickeln möchte.
Janine: So wie du das sagst, das betrifft dich wahrscheinlich auch persönlich.
Helena: Ja, so für unsere letzte Folge zum Thema künstliche Intelligenz über die Bildgenerierung hatten wir, also konnte ich das alles selber auf meinem eigenen Rechner machen. Mittlerweile ist das deutlich schwieriger geworden, weil für viele dieser Modelle eher so 24 Gigabyte Grafikspeicher benötigt werden. Wobei es auch immer wieder mal Software gibt, die angeblich auch auf dem normalen Rechner laufen soll. Das habe ich jetzt noch nicht ausprobiert. Aber sobald wir das alles getestet haben und mehr darüber sagen können, werden wir bestimmt auch mal eine Folge zu diesem Thema machen. Ansonsten war ich auch mal wieder auf einer Veranstaltung zum Thema. Was ist denn gerade so los hier mit Computern und so? Und da war ChatGPT auch einfach das große Thema, dass man damit unheimlich viel machen kann, wie zum Beispiel Excel-Dateien analysieren oder Grafiken erstellen und all solche Dinge. Das sind natürlich dann Features, die der kostenpflichtigen Version vorbehalten sind. Und ChatGPT ist mit irgendwie 20 Euro im Monat doch relativ teuer dafür, dass man vielleicht mal nur ein bisschen damit rumspielen möchte. Es gibt allerdings ja auch die kostenfreie Version. Und ja, eine Sache, die auch mir aufgefallen ist bei so einer Veranstaltung ist ja, die Wörter, mit denen man irgendwie so Data Science Anwendungen bewirbt haben, sich doch stark geändert. Also niemand hat das Wort Big Data noch benutzt. Das war vor einigen Jahren das große Ding oder irgendwie Data Mining. Ist schon länger irgendwie nicht mehr so interessant, scheinbar als Begriff. Dafür neu hinzugekommen ist das sogenannte Prompt Engineering. Also das meint letztlich, was für Texte man sowas wie ChatGPT oder auch Stable Diffusion für die Bildgenerierung oder ähnlichen Modellen sagen soll als Begriffe, damit es das Richtige tut. Und das kann man eben auch in der kostenlosen ChatGPT Version zum Beispiel benutzen, indem man immer den Kontext gleich mit liefert, wer man ist, in welchem Kontext man handelt. Das kann man standenmäßig einstellen und dann muss man das nicht mehr jedes Mal sagen, weil je nachdem, wie der Kontext ist, gibt einem dieses Sprachmodell ja unterschiedliche Dinge. Und deswegen ist das offenbar auch gerade ein großes Thema, auch für die Leute, die nur ein bisschen damit arbeiten und nicht auch selber die Software entwickeln. Ein anderes Ding ist, ich meine ChatGPT ist ja eindeutig gehypt worden dieses Jahr und die letzten Jahre gab es ja durchaus so Hypes wie Blockchain oder NFTs und ich würde sagen, dass das, was ChatGPT kann, etwas ist, was uns auch langfristig erhalten bleiben wird und mehr ist als die anderen Hypes, die ich gerade erwähnt habe. Selbst wenn am Ende die Software nicht mehr ChatGPT heißen wird, sondern vielleicht anders wie Copilot, wie die Marke, die Microsoft jetzt gerade verwendet oder so. Aber welche Software sich dann in zehn Jahren oder so durchgesetzt, das weiß ich nicht und vielleicht gibt es auch für verschiedene Anwendungen ganz viele verschiedene. Aber die zugrunde liegende Technologie, würde ich schon erwarten, bleibt vorhanden und wird unser aller Leben weiterhin in irgendeiner Form beeinflussen.
Janine: Ja, das glaube ich auch. Also es gibt Kritikpunkte, die man daran definitiv üben kann und soll und auch nicht aus den Augen verlieren sollte, aber im Wesentlichen existiert es und wird benutzt und allein deswegen ist es schon wichtig, sich damit zu beschäftigen, was es ist, wie es funktioniert und so weiter.
Tut sich noch was bei der Bildgenerierung? (00:27:47)
Janine: Ja, dann kommen wir doch mal gleich rüber zu den konkreten Data Science Themen 2023 und fangen mit der Bildgenerierung an. Was hast du denn dazu noch hinzuzufügen?
Helena: Ja, genau. Und in der Folge ging es insbesondere um Stable Diffusion, was eine Software ist, die man eben auch auf dem eigenen Rechner kostenfrei einsetzen kann. Und nicht nur diese Software, sondern auch andere basieren auf dem sogenannten LAION-Datensatz, und was mich da jetzt überrascht hat im Laufe des Jahres, gab es irgendwie eine Meldung dazu, in dem dann irgendwie plötzlich von deutschen Gerichten die Rede war, so dass ich mir das nochmal genauer angeguckt hatte und wenn man bei denen im Impressum guckt, dann steht da, dass das irgendwie ein deutscher Verein ist, der noch eingetragen werden solle laut Impressum. Aber das heißt, dass es tatsächlich unter deutsches Recht fällt, die Trainingsdaten. Und hier gibt es durchaus das Thema Data Mining, das nach deutschem Recht, soweit ich das beurteilen kann – ich habe nichts mit Jura zu tun, also ist das nur eine Einschätzung eines Laien. Ja, aber soweit ich das verstanden habe, ist nach deutschem Recht unter bestimmten Voraussetzungen Data Mining im Internet erlaubt. Und so wie ich das verstehe, würde es nach deutschem Recht ausreichen, wenn man die robots.txt, das ist so eine Datei, die man auf Servern hat, in denen drinsteht, ob Google zum Beispiel alle Seiten in die Suchmaschine aufnehmen darf, oder nicht, dass man auch da eben Bilder drüber schützen kann, vor in Trainingsdaten aufgenommen zu werden. Und wenn man das nicht gemacht hat oder das nicht tut, dann hat man so gesehen die Einwilligung gegeben, beziehungsweise ist es eher ein, man muss dem halt aktiv widersprechen. Aber das kann man auch. Ich bin mal gespannt, was jetzt in Bezug auf die Copyright-Klagen, die es da gibt, herauskommt. Und wenn es dann irgendwelche Urteile gibt, werden wir sicherlich in einem der nächsten Jahresrückblicke auch nochmal drüber reden.
Janine: Ja.
Helena: Und was ich auch gesehen habe, ist, es gibt die Malsoftware Krita. Das ist so eine Software, mit der man, wenn man digital malen möchte am Computer, gut arbeiten kann. Die ist auch Open Source und kann einfach heruntergeladen werden. Dafür gibt es jetzt eine Stable Diffusion-Integration. Das heißt, man kann sich Stable Diffusion dann entweder auf dem eigenen Rechner laufen lassen, notfalls kann man das aber auch über die Cloud machen und das anbinden. Und darüber lassen sich dann Elemente von Bildern, die man selber gemalt hat, im eigenen Stil anpassen. Also, dass dann irgendwie Teile geändert werden sollen oder all die Dinge, die Stable Diffusion halt so kann mittlerweile. Also, wenn man ein Bild gemalt hat oder skizziert hat, dass man das dann generieren lassen soll, dass es dann ausgemalt wird. Ja, dass Details hinzugefügt werden sollen, wenn man an manchen Stellen mehr Details haben möchte. Solche Sachen lassen sich damit machen. Und das betrifft jetzt nicht nur diese Software Krita, sondern eben auch die ganzen Adobe-Programme wie Photoshop, die jetzt sehr viele von diesen KI-Tools drin haben, mit denen sich Bilder bearbeiten lassen. Das heißt, auf der einen Seite wurden jetzt für solche Trainingsdaten Daten von Künstlern teilweise ungerechtfertigterweise genutzt, ohne dass sie das wollten. Auf der anderen Seite können jetzt viele Künstler auch einfach damit arbeiten, ohne dass es alles generiert ist, sondern nur Teile vielleicht ein bisschen vereinfacht werden dadurch. Gerade bei der Fotobearbeitung gehe ich mal davon aus, dass das auch dauerhaft genutzt werden wird. Wenn man jetzt irgendwie einen schönen Strand fotografiert und die Leute raus editiert haben möchte oder den Müll.
Janine: Das kann ich mir auch vorstellen.
Kann Whisper inzwischen mehr? (00:31:42)
Janine: Ja, kommen wir mal von Bildern zur Sprache. Wir haben Whisper angefangen zu benutzen. Und zwar stich letzte Jahresrückblicks-Folge, also Folge 34, das war die erste, haben wir unsere Audiodateien, unserer Podcast-Folgen, eben Whisper zugeworfen, was Helena auf ihrem Server installiert hat, um eben unsere Folgen komplett zu transkribieren, in der Hoffnung, damit auch eben so ein bisschen Barrieren abzubauen beziehungsweise Inhalte leichter zugänglich zu machen. Whisper ist etwas, das auch durch OpenAI entwickelt wurde. Es ist auf GitHub verfügbar. Es gibt inzwischen, ich glaube, mehrere Versionen, Ableger, Verbesserungen und nicht nur noch das Originale, wie OpenAI es bereitgestellt hat. Im Sommer hatten wir schon mal eine Folge gemacht mit einem Fazit, was uns bisher so aufgefallen ist, wie so das Experiment bisher für uns gelaufen ist. Das war Folge 40, wie nutzen wir Whisper für Transkripte. Und da hatten wir kurz zusammengefasst so das Fazit, dass im Vergleich zu den selbst angefertigten Shownotes, die recht ausführlich mit Stichpunkten bestückt waren, hat uns das schon enorm Zeit gespart. Es hatte allerdings auch Grenzen. Wir haben so ein kleines Experiment gemacht und Menschen auch Stellen transkribieren lassen und das miteinander verglichen. Was Menschen vor allem tun, ist auch Emotionen abbilden in Transkripten, haben wir dabei festgestellt. Also quasi Metadaten zum reinen Text mit aufgeführt, wie wenn eine von uns gelacht hat oder ähnliche Stellen. Und was auch die Menschen gemacht haben, was Whisper noch nicht gemacht hat, war in Sprechende zu unterteilen, also vorzuschreiben, wer was gesagt hat. So, das waren so die Sachen, die uns aufgefallen waren, die Whisper nicht tat. Ich habe jetzt letztens mal mit einer anderen Whisper-Installation, die auf einem Windows-Rechner lief und für die Grafikkarte optimiert war und nicht auf einem anderen Speicher lief, eine Folge transkribiert. Und da ist mir etwas aufgefallen. Bisher war es immer so bei Helenas-Installation, dass die Gender-Gaps, die wir sprechen, mit einem Binnen-I markiert waren. Und bei der letzten Transkription auf dem anderen Rechner habe ich dann erstmals das Sternchen als Gender-Gap gefunden und auch erste Versuche, die Sprechenden voneinander zu unterscheiden. Ich weiß zwar nicht, warum wir Siebert und Dominik heißen.
Helena: Ja, Sprechende werden unterschieden, aber mit völlig erfundene Namen.
Janine: Ja, manchmal auch nur mit den Buchstaben als Abkürzung. Und ja, das war auf jeden Fall sehr interessant. Das hat auch nicht an allen Stellen funktioniert, das tauchte einfach random im Text auf. Aber ich nehme das mal als Zeichen dafür, dass es anfängt, auch bei Whisper die Stimmen tatsächlich zu unterscheiden und dass sich das dann vielleicht noch ausbaut und demnächst besser funktionieren wird.
Helena: Ja, aber so wie das bisher von den Trainingsdaten her funktioniert, ist es ja doch eher so, dass es einfach Text versus Tonaufnahme im Training verwendet. Und das Risiko, was ich da sehe, ist, naja, Leute wie wir und andere auch schreiben halt die Namen noch zusätzlich davor bei dem Transkript. Aber diese Information steht ja nirgendwo in dem Ton. Und bis Whisper raus hat, dass die Namen vielleicht doch im Ton existiert haben oder dass man die vielleicht extern zufüttern sollte, ich glaube, da müssten die auch die Software umbauen und nicht nur das mit Modellen trainieren.
Janine: Ja, also ich kann mir dann vorstellen, dass man vielleicht so Angaben macht. Zum Beispiel, wenn ich Whisper starte und sage, transkribiere diese Folge, sage ich ja auch, gib mir übrigens bitte aus, wie lang es gedauert hat, das zu transkribieren. Und dann kann ja auch dazu gesagt werden, zwei Sprechende, Speaker 1 Name sowieso, Speaker 2 sowieso. Also es kann ja in den Befehl, Whisper auszuführen, durchaus mit rein. Aber interessant wäre auf jeden Fall erstmal, das überhaupt sauber hinzukriegen. Auch wenn mir dann Siebert und Dominik heißen, dann kann ich das mit Search and Replace trotzdem recht zügig ändern.
Helena: Ja, aber Whisper hat halt nicht den kompletten gehörten Text als Kontext, sondern der Kontext ist ja noch relativ gering. Das hatten wir ja in der Folge. Ich weiß jetzt nicht, ob, also es wurde ja ein neues Modell veröffentlicht, was jetzt eben wahrscheinlich zu diesen Sternchen und den Benennungen geführt hatte. Ob das jetzt auch einen längeren Kontext mitspeichert, aber der war ja so kurz.
Janine: Das stimmt.
Helena: Das kann ich mir nicht vorstellen, dass das sonderlich viel hilft.
Janine: Du meinst, es scheitert daran, dass die einzelnen Sprechabschnitte so lang sind, dass quasi der andere Sprechende aus dem Puffer rausgefallen ist?
Helena: Ja, genau. Es werden ja immer nur so und so viele Zeilen nochmal wieder als Kontext geliefert, die nur wenigen Sekunden entsprechen oder so. Und dann geht das, glaube ich, verloren einfach über die Zeit.
Janine: Ja, das kann sein, natürlich. Daran hatte ich jetzt gar nicht gedacht. Stimmt. Ja, wir werden das weiter beobachten. Vielleicht haben wir da nächstes Jahr dann mal ein Update zu
Wie gut sind Audio Deepfakes inzwischen? (00:37:01)
Janine: Was ich vorhin noch meinte, ist, dass es ja nicht nur Sprache zu Text gibt, sondern auch Text zu Sprache. Und da kommen die Audio-Deepfakes ins Spiel, dass halt Texte mit beliebigen Stimmen, von denen Stimmproben existieren, vorgelesen werden können. Da gab es einige verschiedene Sendungen, Podcast-Folgen, Nachrichtensendungen schon zu und haben da über Deepfakes geredet. Wir verzichten jetzt selbst auf diesen Kniff unserer eigenen Stimmen, einmal zu faken, was in vielen dieser Sendungen passiert. Eine sehr gute Sendung möchte ich aber empfehlen zu dem Thema. Das fand ich, war die Folge Deepfake bei Anruf Klon von 11KM zu finden in der ARD Audiothek. Da kommt Svea Eckert zu Wort und spricht eben über Audio-Deepfakes, die mit Hilfe von KI erstellt werden. Und ein wichtiges Thema dieser Folge ist halt so die Frage, wie sehr können wir Stimmen und ihre Echtheit eigentlich noch vertrauen und was resultiert daraus? Und es geht da auch um Betrug, nämlich darum zum Beispiel, dass Firmenchefs gefaked werden und sich so Geld von Firmen erschlichen wird. Aber solche Fakes können uns auch im kleinen und im privaten Raum betreffen, wenn wir zum Beispiel an diese ganzen Enkeltrick- oder Schockanrufe denken. Ja, das kann fast alle Menschen betreffen. Also Helena's und meine Stimme zum Beispiel sind ziemlich leicht zu kopieren. Wir sind in diesem Internet zu finden. Unsere Stimmdateien sind zu Stunden aufgefüllt.
Helena: Ja.
Janine: Und ja, es gibt es auch von vielen anderen Menschen, die etwas übers Internet teilen. Von daher ist sowas natürlich ein leichtes Ziel. Aber das kann auch einzelne Menschen betreffen, zum Beispiel durch Anrufe, dass Bandansagen von der Mailbox aufgenommen werden oder irgendwelche Fake-Umfragen stattfinden, wobei die Stimme aufgenommen wird. Und mit nur relativ wenig Sprechzeit kann eine Stimme schon ziemlich gut nachgebildet werden. Deswegen finde ich es auch wichtig, also es ist sowieso wichtig mit der Familie und vor allem mit Menschen, die etwas unbedarfter sind, vielleicht darüber zu reden, was solche Anrufe bewirken können, genauso wie Phishing-Mails zum Beispiel. Aber ja, da vielleicht, ja, Vertrauen ist halt schwierig geworden dadurch. Und eventuell wäre es an der Zeit, mit einzelnen Menschen vielleicht so eine Art Codewort abzusprechen, womit sie checken können, gerade bei so Schockanrufen wie ich hatte einen Autounfall, habe Fahrerflucht begangen oder ich wurde verhaftet oder ich brauche Geld. Gerade bei solchen Anrufen einfach nachhaken zu können und auf ein bestimmtes Stichwort zu warten, ob das jetzt real ist oder nicht.
Helena: Ja, ich meine, solche Sachen kommen ja auch gerne dann von der falschen Nummer, wenn sie gefakt sind. Und bisher gab es da vor allen Dingen ja so SMS, wo es dann oft schon gereicht hätte, einfach mal zu fragen, ja, wie heißt du denn überhaupt, wenn du meine Tochter bist? Das hatten vielleicht viele mittlerweile im Familienumfeld schon mal erlebt. Aber in dem Moment, wo der Angreifer tatsächlich recherchiert hat, wie die Familienverhältnisse sind und eine Stimmaufnahme hat und einen so anruft, reicht das dann ja nicht mehr, nach dem Namen zu fragen. Die Stimme ist ja offensichtlich schon verwendet worden. Und ja, man kann nur davon ausgehen, dass diese Art von Betrug immer häufiger wird.
Janine: Ja, und auch einfach ins Blaue hinein. Also ob sich die Menschen vorher wirklich informieren oder nicht. Es ist ein Leichtes, eine Stimme aufzunehmen, einen Text zu generieren und zu gucken, ob es zufällig passt. Also ja, das muss noch nicht mal sehr ausgefeilt sein. Und der Moment, auf den gezählt wird, ist ja auch das Schocken und das Überrennen mit Informationen, zu einer Handlung zu drängen und so. Also ja, schon wichtig, mit Menschen darüber zu reden, was inzwischen möglich ist, finde ich.
Helena: Ja.
Wo steht chatGPT nach einem Jahr? (00:41:00)
Helena: Ja, was inzwischen möglich ist. Ich will nochmal auf das Thema Chat-GPT zurückkommen. Also letztes Jahr 2022 hatten wir so als Jahr der Bildgenerierungsmaschinen gesehen. Und 2023 ist jetzt eindeutig das Jahr der großen Sprachmodelle. Und das GPT-Modell ist eins davon. Und das gibt es eigentlich auch schon seit mehreren Jahren. So, GPT-3, was so die Grundlage von Chat-GPT dann war, haben wir schon im Jahresrückblick 2020 erwähnt. Aber es war halt nicht einfach zugänglich und nicht leicht zu benutzen. Und Chat-GPT wurde ja auch schon im letzten Jahr Ende November veröffentlicht. So, dass es dann auch schon im letzten Jahresrückblick Erwähnung fand. Ja, und seitdem ist einiges passiert. Insbesondere gibt es seit Februar dann eben auch die kostenpflichtige Version. Am Anfang war das ja nur eine Demo, wo jede Person irgendwie teilnehmen konnte. Bei der kostenpflichtigen Version kann man sich zum einen daraus rauskaufen, dass man selber als Trainingsdatum benutzt wird. Aber die kann auch eine ganze Menge andere Sachen, ja, die sich auch im Laufe des Jahres verbessert haben. So, auch im Februar integriert dann Microsoft Chat-GPT und investiert auch sehr viel Geld da rein. Und es wird dann eben die Suchmaschine Bing in, also die Suchmaschine von Microsoft heißt Bing. Und da wird Chat-GPT integriert und nennt sich dann auch Bing Chat. Ja, am 23. Februar veröffnet Meta, das ist die Firma, die früher mal Facebook hieß und jetzt Facebook unter anderem noch betreibt, sowie WhatsApp und Instagram. Die veröffentlichen das Modell LLAMA. LLAMA ist letztlich auch von Large Language Model inspiriert als Name. Also LLM ist so die Abkürzung typischerweise. Und hier ist das Besondere, dass das Modell geleakt wird, also sie veröffentlichen das Modell an sich, aber wie das dann trainiert, welche Werte man wo eintragen muss, war eigentlich geheim. Das wird aber geleakt innerhalb der ersten Woche und ist seitdem die Basis für viele Open Source Large Language Models. Und das ist insofern interessant, als dass eine Sache, die eben bei dieser ganzen künstlichen Intelligenz eine Rolle spielt, ist, wenn man erstmal einen Trainingsstand hat, und ein Modell, dann kann man von da aus weiterarbeiten und muss nicht mehr alle Ressourcen haben, die man vorher investiert hat. Und deswegen war eben dieses LLaMA sehr nützlich für viele Leute, um eigene Modelle und eigene Entwicklungen anfangen zu können. Ja, am 14. März wurde dann GPT-4 veröffentlicht, also die neueste Version, die sich allerdings nur über die Bezahlvariante von ChatGPT nutzen lässt. Und auch im März, am 21. März zeigt Google, dann das erste Mal BART, was so die Konkurrenz zu ChatGPT sein soll. Im Juni haben dann zwei Anwälte zugegeben in den USA, dass sie ChatGPT für eine Verteidigung in einem Fall verwendet haben. Und in diesem Verteidigungsschriftsatz wurden verschiedene nicht existente Fälle als Referenz von ChatGPT halluziniert. Das machte dann große Schlagzeilen und zeigt einfach nochmal, wie unzuverlässig ChatGPT auch sein kann.
Janine: Ja, beziehungsweise nicht wie unzuverlässig, sondern was es einem vorgaukelt.
Helena: Ja, wenn man zu sehr bedrängt, dann erfindet es einfach Dinge, die nicht stimmen. Und das ist ja durchaus etwas, was alle, die das schon mal ausprobiert haben, auch erlebt haben. Es ist auf der einen Seite sehr nützlich, auf der anderen Seite darf man dem auch nicht alles glauben. Im September bekam ChatGPT dann die Möglichkeit zu sprechen. Also es gab ja vorher schon so Assistenten wie Siri und Alexa, die geredet haben, die ja auch eingeschränkt nützlich waren. Jetzt kann ChatGPT sowas in der Art auch. Man kann jetzt Fragen per Worte stellen und kriegt dann auch eine Antwort. Und letztlich werden auch solche Sachen wie eben Siri und Alexa durch solche Sprachmodelle langfristig sicherlich auch verbessert werden. Ja, man kann ChatGPT jetzt auch Fotos zeigen und Fragen zu Teilen des Fotos stellen. Also es ist jetzt nicht mehr nur rein Sprache, sondern die haben eben auch die Bildmodelle da rein integriert.
Janine: Das wird inzwischen auch schon zum verbesserten Shopping-Erlebnis im Internet benutzt, in dem Fotos von Produkten geteilt werden können und die KI-Suchmaschine sagt einem dann, wo man das zu welchem Preis bekommt.
Helena: Echt?
Janine: Ja.
Helena: Das kann ja dann eigentlich nicht ChatGPT sein, weil die auch in der Bezahlvariante jetzt nicht die neuesten Infos haben.
Janine: Nee, das läuft, glaube ich, tatsächlich. Wo hab ich denn das letztens gesehen? Ja, ich meine, Google macht dafür Werbung oder so.
Helena: Ach so.
Janine: Ja, genau.
Helena: Ja, Google macht Werbung. Nachdem deren Bart-Start erstmal total gefloppt ist, weil das Modell noch nicht fertig war, das ist das erste Mal verkündet worden, machen sie jetzt Werbung. Aber das greifen wir vor. Denn im Oktober hat Google das sogenannte Copyright Shield für ihre AI-Nutzer angekündigt, was im Prinzip manche Nutzer, die bestimmte von ihren AI-Tools kostenpflichtig nutzen, davor schützen soll, wenn sie jetzt Copyright-Claims bekommen, weil das, was sie da generiert haben, irgendwie Copyright verletzen würde, dass dann Google eben sie dann gerichtlich dagegen verteidigen würde und notfalls auch für die Kosten aufkommen würde. Wie viel man davon halten mag und ob man sich darauf verlassen kann, das weiß ich nicht. Aber auch Open AI, die Firma hinter ChatGPT, hat dann auch was Ähnliches irgendwie verkündet. Ja, und im November gab es dann die Nachricht, dass ChatGPT pro Woche von 100 Millionen verschiedenen Menschen verwendet wird und es 2 Millionen Entwickler*innen gibt, die Zugriff auf deren Programmierschnittstelle haben, um eigene Anwendungen auf Basis von ChatGPT zu entwickeln.
Janine: Das klingt nach einer Menge.
Helena: Das ist definitiv eine Menge. Also man kann es ja nicht nur selber benutzen, sondern man kann eben auch das als Schnittstelle benutzen und eigene Entwicklungen machen. Und im Prinzip heißt 2 Millionen EntwicklerInnen, dass jede große Firma irgendwie damit arbeitet. Ja, was auch im November passiert, ist es dann, dass bei Open AI die Firma hinter ChatGPT erst die Führungsriege rausgekegelt wurde, also deren Chef. Inzwischen wurde er wieder eingestellt. Keine Ahnung. Also ich meinte ja schon, wer weiß, ob es Open AI und ChatGPT in 10 Jahren noch in dieser Form gibt und ob die dann immer noch die Position haben, die sie jetzt haben als Innovator und Marktführer. Wer weiß das schon? Solche Machtkämpfe innerhalb einer Firma können natürlich genau das auch langfristig verhindern, weil das Vertrauen schwindet. Wer weiß. War auf jeden Fall einiges Chaos im November um die Firma. Ja, was im Dezember passieren wird, das wissen wir jetzt noch nicht.
Janine: Man darf gespannt sein, wo das alles hinführt. Oh, Moment. Ich habe da noch was zu. Genau. Es ist nämlich zum Beispiel auch Stand 27.11. zu einem Abkommen zum Schutz vor KI-Missbrauch geschlossen worden. Und zwar ist das ein internationales Abkommen, in dem sich 18 Länder, darunter auch Deutschland, dazu entschlossen haben, für mehr Kontrolle von Anbietern von KI-Modellen zu sorgen. Allerdings ist das natürlich mal wieder so eine Art Resolution. Das ist eine recht unverbindliche Geschichte. Es ist eine Absichtserklärung. Und es gab ja auch in diesem Jahr einige Länder schon, die die Nutzung zum Beispiel von ChatGPT in ihrer Entscheidungsdomäne untersagt haben. Also ja, da wird sicher auch noch einiges passieren. Und man darf gespannt sein, wie sich das entwickelt.
Helena: Ja.
Was haben wir sonst noch gefunden? - Die Bennu-Proben (00:48:49)
Janine: Gut. Ich finde, das war genug künstliche Intelligenz für den Moment.
Helena: Ja.
Janine: Es ist ja ein kurzer Ritt durch die verschiedenen Themenbereiche, die damit zusammenhängen. Wir hatten aber auch noch andere Themen in diesem Jahr, die wir auch spannend fanden und wo wir denken, vielleicht noch eine interessante Nachricht zum Jahresende jetzt gefunden zu haben, womit wir das ergänzen können. Ich fange mal damit an, indem ich an Part 1 meiner Lieblingsfolgen anknüpfe, nämlich an die Asteroiden. Und als die Folge gerade rauskam, kam auch eine Raumsonde zurück zur Erde und hat hier eine Kapsel abgeworfen. Und in dieser Kapsel befanden sich oder befinden sich auch noch immer Proben eines Asteroiden, nämlich von dem Asteroiden Bennu.
Helena: Um den es ja in der Folge ging, unter anderem.
Janine: Genau. Das war eine lang angelegte wissenschaftliche Mission, mit einer Kapsel Proben auf diesem Asteroiden zu sammeln und sie dann zur Erde zurückzubringen. Die Sonde OSIRIS-REx ist jetzt auf der Reise zum nächsten Asteroiden. Ich glaube, Apophis möchte sie jetzt besuchen oder soll sie? Und hat hier aber eben Proben zurückgelassen mit Steinen und Staub von Bennu, die dort aufgenommen wurden. Und das kam kurz nach unserer Folge dann hier an. Und das Interessante daran ist, am 20.10. ist zum Beispiel ein Bericht von der NASA erschienen, dass tatsächlich bereits 70 Gramm aufgesammelt werden konnten. Ursprünglich war geplant, dass 60 Gramm zur Erde zurückkommen. Und das Lustige daran ist, dass diese 70 Gramm noch nichtmal aus dem Behälter stammen, sondern aus dem Gerät drumrum um den Behälter, weil das ist natürlich insgesamt aufgetroffen auf dem Asteroiden und hat da auch Reste aufgesammelt. Und gerade sind die Wissenschaftler*innen bei der NASA dabei, auch den Behälter öffnen zu wollen. Allerdings sind zwei der 35 Bolzen oder Verschlussmechanismen, die dieses Ding sichern, defekt und können nicht geöffnet werden. Ja, jetzt wird in den nächsten Wochen noch überlegt und geforscht, wie da rangekommen werden kann, ohne dass die Probe kontaminiert wird. Einfach aufbohren wird nicht funktionieren. Dann sind Metallreste mit drin. Und das Ganze kann auch nur in einem sehr beengten Raum stattfinden, weil diese Kapsel in einer Kiste ist, wo die Erdatmosphäre keine Rolle spielt, damit die Proben nicht kontaminiert werden können. Das ist in so einer sogenannten Glovebox, wo man so mit so Handschuhen reinfassen kann. Deswegen ist der Raum auch recht beengt und die Möglichkeiten. Ich glaube, das ist gerade frustrierend und spannend gleichermaßen für die Forschenden, darin zu arbeiten.
Helena: Ja, den ersten Ergebnissen nach bestanden die Staubproben vor allem aus sehr viel Kohlenstoff und Wasser. Und die Kohlenstoffverbindungen waren teilweise sogar in organischen Verbindungen vorliegend. Was genau das jetzt im größeren Kontext heißt, muss man dann später mal gucken, wenn noch mehr untersucht wurde.
Janine: 25% der Proben werden auf die ganze Welt verteilt an Wissenschaftler*innen und Einrichtungen. Der Rest verbleibt bei der NASA, wovon ein kleiner Teil tatsächlich unangetastet bleiben und gleich gut verpackt werden wird, um nämlich mehrere Jahrzehnte eingelagert zu werden, damit Forschende der nächsten Generation potenziell die Möglichkeit haben, mit eventuell verbesserten Untersuchungsmethoden und Gerätschaften dieses Material nochmal zu untersuchen und vielleicht zu anderen, besseren, feineren Ergebnissen zu kommen. Was ich auch eine ganz coole Praxis finde.
Helena: Ja.
Janine: Dass die Menschen nicht denken, nur wir jetzt können alles erschließen, was dahinter steckt.
Helena: Ne, die Geschichte hat gezeigt, dass es oft eine gute Idee ist, noch zu warten, weil früher konnte man manche Dinge nur untersuchen, indem man sie kaputt gemacht hat. Während es mittlerweile so mit verschiedenen Röntgen oder Mikroskopieaufnahmen auch Varianten gibt, wo man nicht Dinge zerstören muss. Und die kann man jetzt gerne machen, aber es ist immer gut, auch Dinge erstmal unangetastet zu lassen.
Was haben wir sonst noch gefunden? - Eine Ketamin-Sudie (00:53:01)
Janine: Welches Thema hast du denn nochmal ausgegraben?
Helena: Ja, vor zwei Jahren hatten wir eine Folge über Drogen gemacht und dabei ging es auch unter anderem um Ketamin, was mittlerweile bei der Behandlung schwer therapierbarer Depressionen eingesetzt wird, auch in Deutschland. Da gibt es eine neue Studie zu. Ja, im Grunde ist das Problem, was die Studienautoren bei Ketaminbehandlung sehen, dass auch bei einer niedrigen Dosis, die man gegen Depressionen einsetzt, immer noch bestimmte Nebenwirkungen oder vielleicht ist es auch die Wirkung, wer weiß das schon so genau, existieren, die dazu führen, dass die Leute, die tatsächlich das Medikament nehmen, es relativ schnell merken, dass sie wirklich das Medikament nehmen und nicht den Placebo. Und da hatten die dann die These, dass es vielleicht ja sein kann, dass wenn man merkt, man nimmt wirklich das Medikament und nicht den Placebo, dass sich der Placebo-Effekt eben verstärkt. Also es gibt durchaus Nachweise, dass der Placebo-Effekt auch von der Erwartungshaltung abhängt. Wenn man damit rechnet, das wirkt eh nicht, was man nimmt, wirkt es halt auch schlechter oder auch der Placebo wirkt dann eben schlechter, als wenn man davon ausgeht, dass es wirkt. Was die deswegen gemacht haben, um das auszuschließen, ist bei Leuten, die für eine Ketaminbehandlung in Frage kommen und gleichzeitig aber auch ein anderer körperlicher Eingriff, der eine Narkose fordert, eh stattfinden sollte, dass man das kombiniert hat und dass man dann eben bei 40 Leuten das gemacht hat, dass man dann sagt so, ja, ihr kriegt jetzt eh eine Narkose und wir geben euch jetzt entweder ein Placebo oder eben das Ketamin intravenös und die merken dann aber nicht, ob sie das Medikament genommen haben oder nicht, weil sie ja in Narkose sind. Und da haben jetzt die ersten Ergebnisse keine nennenswerten Unterschiede wahrgenommen zwischen beiden Gruppen. Also die Leute, die tatsächlich Ketamin genommen haben oder das Placebo, das war relativ ähnlich und auch der Anteil der Leute, die erraten haben, ob sie jetzt Placebo oder Ketamin genommen haben, lag unter 50 Prozent, was ja dann schon heißt, wenn man das so schlecht erraten kann, dass es wirklich nicht offensichtlich ist. Also das ist ja durchaus etwas, was man auch nutzen kann, um zu unterscheiden, können die Leute erraten, ob sie Placebo nehmen oder nicht? Und wenn die das sehr gut können, ist es wahrscheinlich so, dass man irgendwie einen Fehler hat in dem Doppelblindversuch oder dass einfach der Effekt so stark ist, dass man sofort merkt, das funktioniert. Das kann ja auch sein, dass die eigentliche Wirkung so gut ist, dass es gar nicht möglich ist, das vom Placebo nicht zu unterscheiden. Ja, aber das lag hier nicht vor. Man konnte das nicht unterscheiden. Und ja, es lag in beiden Fällen ein relativ guter Effekt vor, weshalb jetzt eine Idee ist, vielleicht funktioniert Ketamin doch gar nicht so gut, sondern die Leute glauben nur, dass es besonders gut wirken würde. Aber es sind nur 40 Proband*innen gewesen. Das heißt, das ist jetzt noch nichts, was irgendwie dem Einsatz von Ketamin in der Therapie von Depressionen, verhindern würde, weil es sehr viele Studien gibt, die eben auch zeigen, dass es sehr viel bringt bei gerade schwer behandelbaren Depressionen. Das kann ja auch sein, dass einfach das, was man spürt, was dazu führt, dass man merkt, dass man das Ketamin nimmt im Vergleich zum Placebo, ja auch genau das ist, was die Wirkung verursacht. Deswegen ist das jetzt keine klare Widerlegung. Aber ich fand die Idee einfach interessant, dass man in solchen Fällen auf diese Weise eben versucht, den Placebo-Effekt noch anders rauszubekommen.
Janine: Ja, auf jeden Fall auch etwas, das interessant ist zu verfolgen, weil ja gerade unter Depressionen leiden ja auch viele Menschen. Und es wäre ja schön, wenn es da etwas gäbe, was auch den Leuten hilft, die da nicht so einfach wieder rauskommen, wobei so einfach in Anführungszeichen in alle Richtungen bitte zu verstehen ist.
Helena: Ja.
Was haben wir sonst noch gefunden? - Waldrapp im Norden (00:57:15)
Janine: Ich habe noch mal ein Thema ausgegraben zur Gartenvögel-Folge und zu Citizen Science. Es gibt Waldrappen. Das sind große Vögel, fast so groß wie Gänse. Sie sind schwarz gefiedert und gehören zur Familie der Ibisse. Es ging ja auch um Vogelpopulationen in der Gartenvogel-Folge. Und die Waldrappen sind eine Vogelart, die einst in Europa ziemlich verbreitet war, aber im 17. Jahrhundert durch Bejagungen und so weiter recht deutlich ausgerottet wurde. Mitte der 1990er Jahre gab es von ihnen nur noch gut 200 Exemplare in freier Wildbahn. Und seitdem bemühen sich verschiedene Projekte darum, die Waldrappen wieder anzusiedeln und die Vogelpopulation wieder aufzubauen. Und deswegen gibt es auch tatsächlich wieder Brutgebiete. Und zwar befinden die sich hauptsächlich in Süddeutschland, Österreich und der Schweiz. Und Waldrappen sind Zugvögel, die woanders überwintern. Sie fliegen noch eine ganze Ecke in den Süden, um dort dann den Winter zu verbringen und dann in die Brutgebiete zurückzukommen. Das heißt, ich sag mal, oberhalb von Bayern sieht man Waldrappen wahrscheinlich extrem selten. Die Vögel sind auch besendert und werden beobachtet. Man kann auch mit einer App das Live-Tracking für die besenderten Vögel verfolgen. Und so kam es dann, dass auch am 28. Oktober sehr schnell festgestellt werden konnte, dass sich etwas sehr Ungewöhnliches ereignet. Nämlich sind circa 23 Jungvögel aufgebrochen und nach Norden geflogen und haben innerhalb von drei Tagen über 1600 Kilometer zurückgelegt mit teilweise einer Fluggeschwindigkeit von bis zu 100 km h. Das müssen sehr gute Windbedingungen gewesen sein, denn eigentlich geben die Forschenden an, dass die so um die 40 bis 50 km h fliegen. Die Gruppe ist nicht die ganze Zeit zusammengeblieben, sondern hat sich zwischendrin auch getrennt. Und gerade deswegen haben die Menschen aus den Waldrapp-Projekten auch dazu aufgerufen, Vogelbeobachtungen zu melden und auch gegebenenfalls mit Bildern zu belegen und zu zeigen, wo die Vögel sind. Es sind einzelne Gruppen unterwegs gewesen, wo auch nicht besenderte Vögel dabei waren, wo dann halt sehr unklar war, wo die hinfliegen, was die machen. Und ja, wie sich vorgestellt werden kann, hier wird so langsam Winter, aktuell liegt hier gerade zum Beispiel ein bisschen Schnee und irgendwann sollten die Vögel eigentlich in den Süden und sind jetzt tatsächlich bis Schweden geflogen, einige von ihnen. Aktuell sagen die Forschenden dazu, da finden sie noch genug Nahrung und gute Bedingungen vor, aber irgendwann wird es zu kalt und wenn sie dann nicht den Sprung in den Süden schaffen, dann ziehen sie nicht in ihr Überwinterungsquartier und werden es schwer haben. Deswegen war es besonders wichtig, da Meldungen zu bekommen und es gibt auch einige Fotos jetzt von den Vögeln in Schweden, was ganz cool ist, sich auch mal anzugucken, weil eigentlich sind die echt ziemlich hübsch. Und ja, das Ding ist nämlich, dass die Jungvögel teilweise selbst noch nie ins Überwinterungsgebiet geflogen sind und wenn sie nicht mit erfahreneren Vögeln auch mal diesen Flug antreten, wissen sie zwar, dass es irgendwie nach Süden geht, aber nicht ganz exakt, wohin wahrscheinlich und es wäre einfach gut, wenn sie mit erfahreneren Vögeln dorthin flögen. Wenn das nicht passiert, dafür gibt es jetzt allerdings inzwischen auch einen Notfallplan. Also es gibt eine Kooperation mit einem Zoo in Schweden, die Vögel sollen dann gegebenenfalls eingefangen und im Zoo überwintert werden, damit sie auch im nächsten Jahr dann wieder freigelassen werden können und dann vielleicht tatsächlich zu ihrem Überwinterungsgebiet fliegen, nachdem sie vorher wieder in ihrem Brutgebiet ausgelassen wurden. Das ist, finde ich, auch wieder ein schönes Beispiel dafür, wie zwar moderne Technik zum Einsatz kommt, indem mit Sendern nachzuverfolgen ist, zu jeder Sekunde, wo sich einer dieser Vögel gerade befindet, aber dann teilweise doch auch die Hilfe von Menschen, die sich in der Natur umsehen, gefragt ist, um nachvollziehen zu können, was diese Vögel machen, gerade wenn nicht die ganze Gruppe Sender mit sich trägt.
Helena: Ja, ist doch echt. Ich wüsste auch gerne, warum sind die in die falsche Richtung geflogen?
Janine: Ja, also im ersten Artikel, den ich auch verlinkt habe, steht so ein bisschen drin, es ist für die Forschenden selbst auch völlig unklar, warum sie sich so verhalten. Es ist absolut untypisch. Eigentlich fliegen die gar nicht so in den Norden und schon gar nicht so weit, aber es wird auch so leicht angedeutet, der Herbst war recht warm. Aktuell sind die Bedingungen noch sehr gut und die Waldrappen fliegen grundsätzlich relativ spät los. Also ja, vielleicht können spätere Untersuchungen oder Beobachtungen zeigen, dass es eventuell mit der Temperaturverschiebung zusammenhängt in der Hinsicht. Aber ja, so genau kann das einfach auch jetzt gar nicht gesagt werden. Es ist auf jeden Fall recht ungewöhnlich, dass die einfach mal nach Schweden fliegen.
Helena: Wenn die da normalerweise eh nicht sind und dann eigentlich nicht nördlicher als Bayern fliegen. Ja, ungewöhnlich. Wir werden uns das nochmal angucken.
Janine: Genau, bin auch ein bisschen angefixt, das Thema weiter zu beobachten.
Was erwartet uns wohl im Jahr 2024? (01:02:38)
Janine: Damit haben wir es eigentlich für dieses Jahr, um das mal so brachial zusammenzuzurren. Die letzte Frage ist eigentlich, was erwartet uns wohl im Jahr 2024?
Helena: Ja, eine Sache, die ich jetzt gerade so beobachte und wahrscheinlich auch im Jahr 2024 wohl noch gelten wird, ist, dass die Relevanz vom ehemaligen Twitter wohl weiterhin irgendwie noch gegeben sein wird, weil es immer mal wieder Nachrichtensituationen gibt, wo ich doch in der internationalen Presse oft Zitate von Twitter dann noch lese, also ehemals Twitter. Während es in Deutschland eigentlich quasi ja ausstirbt und sich immer mehr davon zurückziehen, wie auch dieser Podcast.
Janine: Ja.
Helena: Wir sind da auch schon nicht mehr. Ja, dann würde ich erwarten, dass sich die Anwendung von sowas wie den Sprachmodellen und der Bildgenerierung weiter herauskristallisieren wird. Also, dass es einige Situationen gibt, wo das komplett sinnlos ist, wo man jetzt versucht, damit zu arbeiten. Wird es sicherlich geben, aber auch Dinge, wo es sich sehr nützlich herausstellt.
Janine: Ja, also ich würde zumindest für mich für 2024 sagen, so welches Thema mich da auch so ein bisschen mehr erwartet oder wo ich auch wieder mehr Augenmerk drauf lenken will, ist das Klimathema, weil ich einfach merke, dass ich da gerade komplett den Anschluss verloren habe. Also öfter sehe ich so einzelne Berichte auftauchen, die jetzt so sagen, die jetzt zum Beispiel sagen, ich glaube, der Oktober war der wärmste Oktober seit 125.000 Jahren und solche Dinge. Und das sind aktuell nur noch so Lichtblitze von einem Thema, das so groß geworden ist, dass es fast nur noch Hintergrundrauschen ist. Und da würde ich also von mir selbst einmal erwarten, dass ich da wieder mehr hingucke. Und zum anderen glaube ich aber auch, dass das noch dringender werden wird und auch so Projekte vielleicht mehr in den Fokus rücken müssen, die Sachen voranbringen und nicht sowas wie die Wirtschaft beschwert sich, dass die Klimamaßnahmen die Wirtschaft kaputt machen. Aber was will die Wirtschaft denn noch wirtschaften, wenn die Welt nicht mehr da ist? Ich verstehe es nicht. Aber vielleicht denke ich da auch einfach nicht so sehr in Dimensionen des Geldes. Ja, also ich würde erwarten, dass das Klimathema auch politisch nochmal wieder schwieriger wird und mir erhoffen, dass mehr gute Dinge passieren, Flächenversiegelung aufbrechen, Dinge.
Helena: Ja, wir werden sehen.
Janine: Mehr Petitionen.
Helena: Das bringt ja nur was, wenn auch was daraus folgt.
Janine: Genau das. Und wenn dann so Sachen wie das 49-Euro-Ticket wieder zur Diskussion stehen und Mobilität wieder auf den Individualverkehr zurückgezwungen wird oder wieder eingeschränkt wird, ja.
Helena: Ja, wir werden sehen, was passiert.
Fazit (01:05:37)
Helena: Ja, kommen wir zum Fazit dieser Folge. Ich meine, es ist ein Jahresrückblick. Es ist viel passiert in 2023.
Janine: Ja.
Helena: Und vor allen Dingen ist sehr viel im Bereich der großen Sprachmodelle passiert. Und ja.
Janine: Und vieles anderes auf der Welt, was in dem Schnelldurchlauf in unserem Einspieler zu hören war. Einige Themen haben in diesem Jahresrückblick so gar nicht Platz gefunden. Das liegt aber auch daran, weil wir uns thematisch natürlich sehr fokussieren und deswegen bestimmte Teile der Welt auch uns herausnehmen auszuklammern, weil das einfach nicht unser Thema hier ist. Deswegen möchte ich nur einmal sagen, kommt alle gut durch das nächste Jahr, auf das viele Dinge besser werden.
Nächste Folge: Kaffee im Januar (01:06:20)
Helena: Ja. Und wenn wir dann im neuen Jahr sind und es dann darum geht, welche Folge wir zuerst machen, da haben wir uns überlegt, wollen wir uns mal ein paar Statistiken zum Thema Kaffee angucken. Das heißt, ja, wir gucken uns an, wie sich so der Kaffeekonsum über die Jahre entwickelt hat und vielleicht noch das ein oder andere mehr.
Janine: Ja, ich freue mich auf das ein oder andere mehr.
Call to Action (01:06:46)
Janine: Ja, und wenn ihr uns im nächsten Jahr auch wieder begleiten möchtet und unsere Folgen nicht verpassen wollt, dann folgt uns doch auf Mastodon unter at datenleben at podcasts.social oder besucht uns auf unserer Webseite datenleben.de. Hinterlasst uns gerne Feedback, damit das nicht ChatGPT oder irgendein anderer Textdienst übernehmen muss, denn über richtiges, echtes Feedback freuen wir uns immer sehr. Ihr könnt uns da Kommentare posten und könnt uns aber außerdem auch als Data Scientist buchen für Analysen und Projekte und falls ihr Fragen oder Themen habt, uns auch immer anschreiben.
Helena: Ja, dann bleibt mir nur noch für eure Aufmerksamkeit zu denken und bis zum nächsten Mal. Ciao.
Janine: Tschüss.